owned this note
owned this note
Published
Linked with GitHub
<h1 style="display: none;">Hivegrid Spec</h1>
<img src="https://storage.googleapis.com/ethereum-hackmd/upload_0148b70529d1db33bc2eb3113e277668.png" width="600" alt="Hivegrid">
## What is Hive?
Before diving into hivegrid we will go over some preliminary hive information!
Hive is an end-to-end test harness used for integration tests against ethereum clients. It generally works by spinning up 3 types of docker containers working alongside the hive controller:
1) **Simulators** - within hive, tests are grouped by test suites which are grouped by simulators. For example the tests that are specific to the engine api for cancun are grouped within the `engine-cancun` test suite, which is held within the `engine` simulator. Tests are ran within their corresponding simulator container and interact with clients using RPC or p2p.
- **Containers must be rebuilt upon changes to the simulator or tests within the simulator.**
- **Simulator runtime is usually longer than the build time if there is more than 50 tests.**
2) **Clients** - client containers simply contain a single client built with a specific configuration. As before clients can communicate with simulator containers using RPC.
- **Containers are rebuilt when changes to the client branch your are pointing to are made.**
- **Build times can be long depending on the client.**
- **Multiple client containers can exist in one test.**
3) **Hiveproxy** - within this container, a proxy server is run to facilitate communication between simulators and clients (inter-container communication).
- For example when sending an RPC request to a client from a simulator, or recieving a response from a client to simulator, it is achievied by relaying the information via hiveproxy.
- **Practically never needs to be rebuilt.**
4) **Hive Controller:** this component operates externally to the docker environment and acts as the central orchestrator for simulations. Its responsibilities include initializing simulations and managing the lifecycle of both simulator and client containers.
- Upon initiating a simulation, the hive controller starts an API server for the simulator.
- The `HIVE_SIMULATOR` env var directs simulators to the URL for the API server.
- The server allows simulators to launch client containers and report results back to the hive controller.
**From the existing [documentation](https://github.com/ethereum/hive/blob/master/docs/overview.md):**
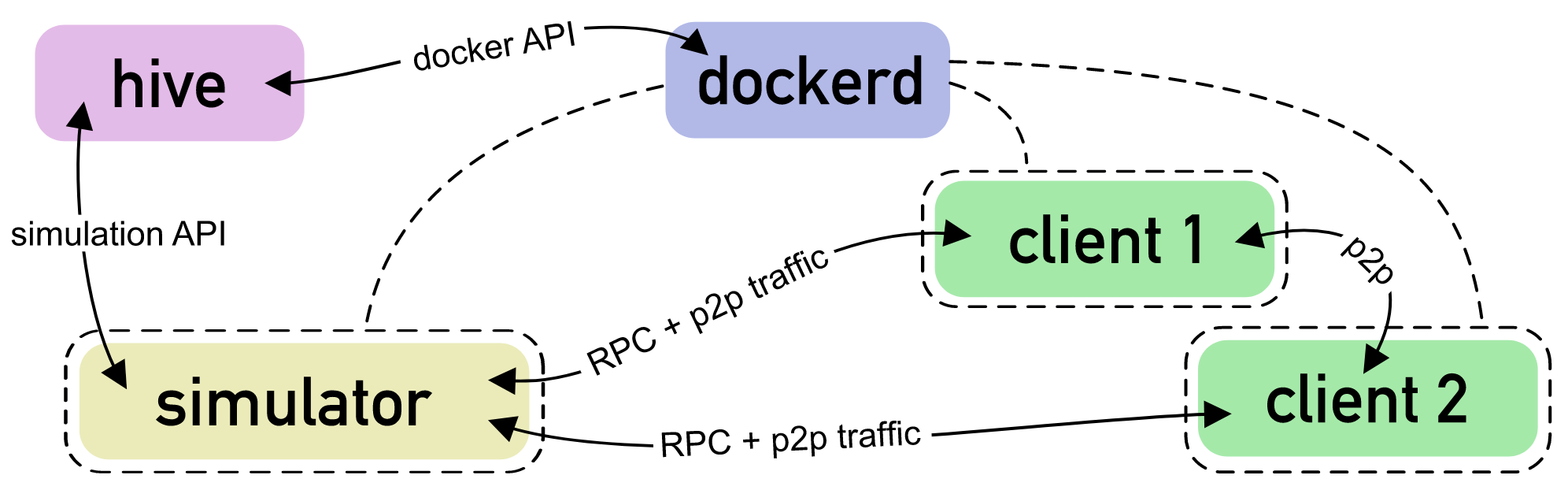
## Current Hive Flow
Running a simulator with hive involves several coordinated steps between the hive controller, simulators and clients. Here is a high level breakdown of what happens when you run a simple command:
```
./hive --sim ethereum/engine --client go-ethereum --sim.limit <test_suite_regex>/<test_name_regex>
```
1) **Hive Controller Initialization:**
- Executes directly on the host system, initializes and begins the simulation process.
- Reads and stores the cli params to determine what simulators and clients are involved for the the simulation.
2) **Docker Image Preparation:**
- The hive controller instructs the docker daemon of the host system to build or pull the required images for the specified simulators and clients using an internal docker API (`internal/libdocker`), in the following order:
- Hiveproxy image: built first as it ensures communication between the docker network,
- Client images: all the client/s specified are then built,
- Simulator images: followed by the simulator/s specified.
- **Note if nothing changes between simulator runs, the cached docker images held within the docker daemon of the host are used and not rebuilt.**

3) **Simulator Commencement:**
- API Server Startup: the hive controller initiates the API server for the simulator, which handles communications and commands between the simulator and itself.
- Hiveproxy Container Launch: the hive controller then launches the hiveproxy container for relaying HTTP requests within the docker network.
- Simulator Container Launch: and then launches the container for the simulator.
- Note that relavant simulator cli variables stored within the hive controller are added as env vars to the simulator container.
- For example, for `--sim.limit` its values are stored within the `HIVE_TEST_PATTERN` env var local to the simulator container.
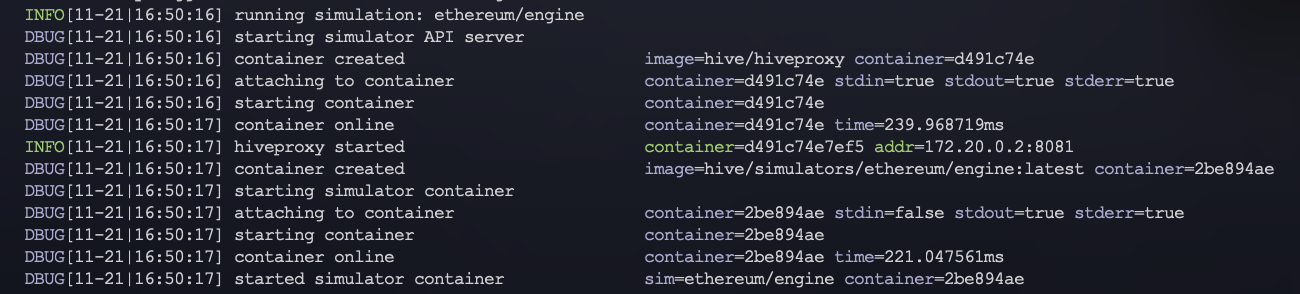
4) **Test Suite & Test Case Filtering:**
- For every test suite defined within a simulator:
- The `HIVE_TEST_PATTERN` env var local to the simulator container (which stores the cli value from `--sim.limit`) is used to filter the test suites to run within the simulator.
- In a similar fashion, for every test case defined with a test suite we also filter using the value defined by `--sim.limit`.
- For example for the `engine` simulator, if we used `--sim.limit "cancun/Blob"` we would filter to only use the test cases that have "Blob" in their name/definition within the `engine-cancun` simulator. See image below:
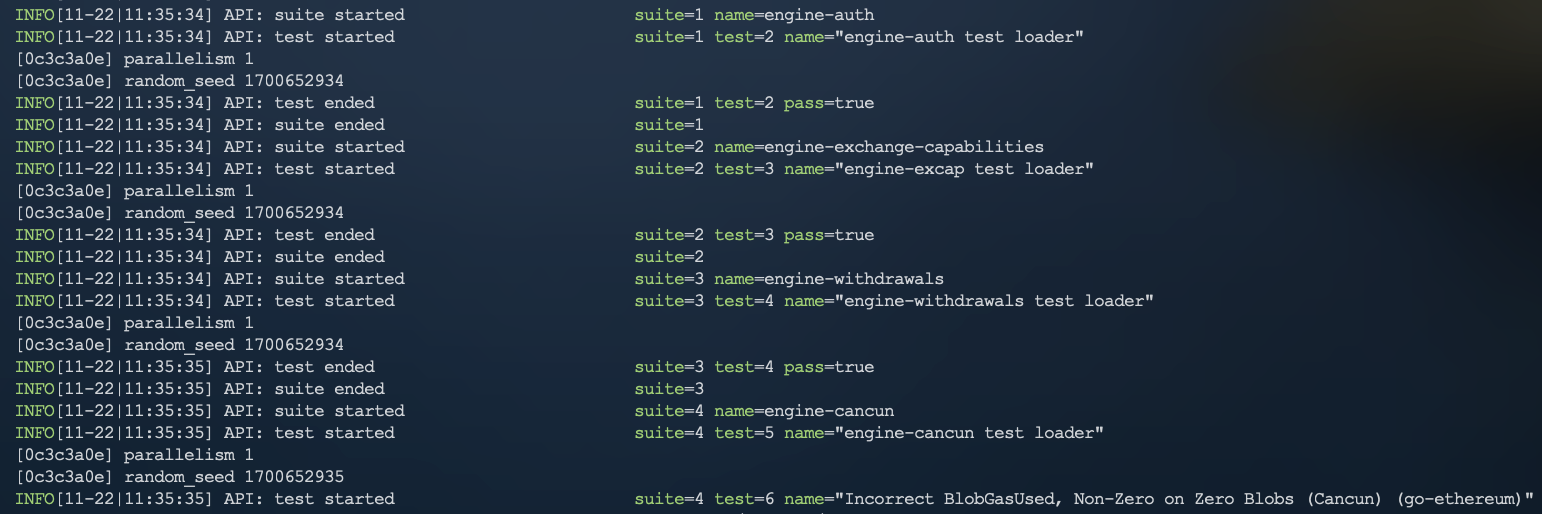
- Note that `--sim.limit` filters using regex. If not used hive will run all tests for every test suite within a simulator.
5) **Test Case Execution:**
- For each filtered test case ran within a test suite within a simulator :P, seperate fresh client container/s are launched.
- These are requested by the simulator depending on the test written from the hive controller using the simulation API.
- When the simulator requests a client instance, the hive controller launches a new docker container using the built client image.
- Client containers are configured using env vars typically defined by the simulator, i.e `HIVE_SHANGHAI_TIMESTAMP`.
- After client/s have finished starting, tests within a simulator will communicate with it/them over RPC or p2p (using the hiveproxy).
- At the end of each test case the client containers will be deleted, see below.

6) **Logging During Simulator Runs:**
- Both simulator and client containers generate logs as part of their operation. These logs can include details about the test execution, interactions (like RPC calls) and errors.
- Currently the hive controller mostly asyncronously dumps the logs for each test case run within `./workspace/logs/`:
- **client specific logs** for each test case run are stored within their own dir: `./workspace/logs/<client_image_name>/`
- with the naming convention: `<unix_timestamp>-<client_container_id>.log`
- **simulator specific logs** for each simulator run (filtered by test suite and test case) so essentially its one big log file:
- with the naming convention: `<unix_timestamp>-simulator-<simulator_container_id>.log`
- **integrated test suite/clients logs**, for each simulator run, multiple big files stored within `./workspace/logs/details/`:
- with the naming convention: `<unix_timestamp>-<simulator_container_id>-<test_suite_index>.log`
- for example if you are running 3 test suites within a simulator you will end up with 3 of these logs.
- **simulator meta logs**, for each simulator run this is created with relavant structured information per test suite and test case, an example snippet for a simulator ran with 1 test suite:
```
{
"id": 0,
"name": "engine-cancun", # test suite
"description": "\tTest Engine API on Cancun.",
"clientVersions": {
"ethereumjs_cancun-git": "9.8.1"
},
"testCases": { # test cases within the test suite
"1": {
"name": "engine-cancun test loader",
"description": "",
"start": "2023-11-06T19:40:42.088327665Z",
"end": "2023-11-06T19:44:09.666043841Z",
"summaryResult": {
"pass": true,
"log": {
"begin": 34165000,
"end": 34165016
}
},
"clientInfo": null
},
},
"simLog": "1699299641-simulator-9bebca1df2edf2e768b8d89e773a7b469f451c376e18dda88b2d926995624aa1.log",
"testDetailsLog": "details/1699299642-9bebca1df2edf2e768b8d89e773a7b469f451c376e18dda88b2d926995624aa1-0.log"
}
```
- `"id": 0,` corresponds to the `<test_suite_index>` for integrated test suite/clients logs.
- `"name": "engine-cancun",` the test suite.
- ` "testDetailsLog": "details/1699299642-9beb...4aa1-0.log"` the integrated test suite/clients log.
- Note the values within `summaryResult/log`:
- currently hiveview uses these to find the location relavant to a specific test case within the integrated log. This needs do be improved.
7) **Post Simulator Run Steps:**
- After a simulator has finished executing all test suites with their respective test cases, the simulator container is deleted followed by the hiveproxy container.
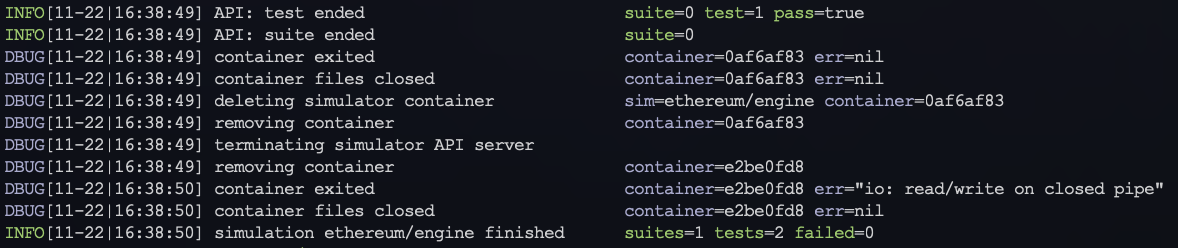
- Note the client containers are deleted after each test case run, so a fresh and new container is used for each test.
- The container deletion is performed inversely compared to the order containers built and launched.
## What is Hivegrid?
Hivegrid is exactly what the name implies: a grid/cluster of hive instances/nodes.
1) Its core or primary usecase is essentially an orchestrator CI/CD system. This would act as an overhaul to the existing system. One that is more maintainable and gives client teams more control & value.
2) The secondary use of hivegrid is simply to improve the run time and UX of running a hive simulator, where anyone can run their hive tests within the grid instead of locally.
- Lets say we want to run all the test suites (and test cases) within the `engine` simulator using the grid! Instead of running `./hive ... --sim ethereum/engine` we would run `./hivegrid ... --sim ethereum/engine`.
- Let's assume we have 10 hive instances within the grid. Currently we have over 200 `engine` tests. Hivegrid would split these tests to run on multiple nodes depending on demand, lets say 4 nodes are used.
- In this case we run 50 tests on each hive node, where each node uses parallelism. Theoretically this has the capability to massively improve the run time when running hive tests. Currently it takes over an hour run only the `engine-cancun` tests locally with no parallelism.
<figure>
<center>
<img src="https://storage.googleapis.com/ethereum-hackmd/upload_b1a63ae78062e0bd58d0ca96c50d8e88.png" width="900" alt="Hivegrid">
</center>
</figure>
## Existing Hive CI
For the current hive CI we run multiple isolated [hive servers](https://github.com/ethereum/cluster/blob/master/hive/ansible/inventories/production/inventory.yaml):
- **EL Cancun tests:** https://hivecancun.ethdevops.io/
- **Interop EL/CL Cancun/Deneb tests:** https://hiveinterop.ethdevops.io/
- **Other EL tests**: https://hivetests.ethdevops.io/
- Should be mainnet tests? Clients need updated/fixed, not currently maintained.
- **EL/CL mix**: https://hivetests2.ethdevops.io/
- Combination of EL/CL tests? Clients also need updated/fixed, not currently maintained.
Within each server we enable a simple [service](https://github.com/ethereum/cluster/blob/master/hive/ansible/roles/hive/templates/hive.service.j2) that simply runs a [bash script](https://github.com/ethereum/cluster/blob/master/hive/ansible/roles/hive/templates/start-hive.sh.j2). This script runs specific hive simulators within an inefficient loop, repeating test runs over and over.
- *One potential hacky solution to the loop is here: https://github.com/ethereum/cluster/pull/881, but hivegrid is the optimal solution.*
Each simulator run within the loop dumps its results within a specific directory. [Hiveview](https://github.com/ethereum/hive/tree/master/cmd/hiveview) a simple front-end for viewing results within
###
Currently we have been running hive tests on the heztner server we were given a while back. We now have a playbook to add and remove users such that they all have separate docker hosts and don't interfere with each other during test runs. I was thinking about opening the server up to other client teams to use for debugging if its useful for them - the main benefit being faster test runs. However if the latter became popular it would be difficult to scale, and its a bit too hacky for me.
The best scalable solution in my mind is to create a grid of hive instances. Lets call it hivegrid, for now with 10 instances/nodes/hives. These could be used to run hive as one would locally. So instead of running ./hive .. you would run ./hivegrid .. specifying that you would like to run the tests on the grid. Theoretically this could make for blazing fast test runs. Especially if we create a fancy auto-updating caching system for client containers. Maybe some instances are specific to each client.
Lets say we wanted to run all the engine tests (there are over 200), depending on hivegrid load we could allocate all 200 engine tests between 4 instances. So thats 50 tests per instance. Each instance could run with parallelism set to 8. If the load is higher due to more users running hivegrid we allocate less instances etc.
Similarly, I've been thinking a lot about future CI/CD for hive, and I feel this could integrate quite well with it. Essentially we would have specific nodes allocated solely to CI. This would make it very easy to for client teams to add to there CI/CD. Assuming we allow for different log outputs/formats it would be as simple as adding the appropriate ./hivegrid command to a client CI.
There are still some more improvements needed for hive before we get to anything like this (especially documentation), however its something I'd be keen to try working on early next year if its feasible. 😄





