owned this note
owned this note
Published
Linked with GitHub
# Blob ILs and distributed block building
## Blob mempool sharding
https://notes.ethereum.org/wcg_u2qORiqpyZ7KbPjRAA?edit
## Inclusion lists
Ideally, we have both of these:
1. Local block building with high blob counts *and low latency*, meaning that even fairly recent blobs can be included
2. ILs with blobs covering the whole blob mempool, produced by nodes downloading only $1/k$ of the blob data, where $k$ is essentially our sharding factor.
## Blobs in ILs
Let's try to understand what are the difficulties in supporting this functionality, by looking at the whole IL pipeline, from IL production to transaction inclusion by the block builder to IL enforcement by attesters. However, since in all case the main challenge is how to determine availability, let's first discuss an issue that shows up in multiple places.
### Multiple independent availability checks
By multiple *independent* availability checks we mean the scenario in which we are checking availability of multiple objects, such as multiple ILs or multiple blob txs, and we do not want their availability to be coupled. Meaning, the check failing for one object would not mean that all objects are considered unavailable.
This is unlike the availability check we make when sampling in PeerDAS, which can be thought of as multiple *coupled* availability checks, since by downloading columns we effectively sample each blob. Crucially, there is no concept of a column being partially available, and so there is no concept of one blob being available while another is not: either we determine the whole matrix to be available or we don't.
In the case of PeerDAS sampling, it is ok for availability of all blobs to be coupled because there's a single actor which is responsible for the availability of *all* blobs. In many other cases, we do not have this luxury. For example, there's many IL proposers, and we do not want the availability of all ILs to be coupled, because a rogue IL proposer might just include unavailable txs. Similarly, there's many blob txs in the mempool with many different senders, and, if we need to determine their availability (like in the vertically sharded mempool case), we want all checks to be independent.
Having established that we might need to carry out multiple independent availability checks, why is that a problem? Essentially, what we want overall is to have a low probability of judging *at least one unavailable object* as available, and each check adds to that probability. For example, consider attesters which see N ILs and need to do sampling on them and only enforce ILs that are available. For each IL, sampling gives us the global guarantee that at most a small percentage of attesters will determine availability incorrectly. However, *a different small set of attesters might be tricked in each case*, so that overall the set of attesters which see *at least one* unavailable IL as available can end up being much larger if there are multiple "attacking ILs".
### IL production: IL proposers
- **Horizontally sharded mempool**:
- *Trivial availability check* ✅: here, proposers just fully download blob transactions, so there is no problem of determining availability.
- *Many ILs required to cover the mempool* ❌: The downside is that, since we want ILs to only require downloading $1/k$ of all blobs, we need $k$ ILs to cover the whole mempool, or more precisely $rk$, where $r$ is a redundancy factor (e.g., 8 or 16). Concretely, say we shard the blob mempool in 32 "horizontal" shards, such that each node only downloads 1/32 of all blob transactions and blobs (horizontal because we always represent blobs are the rows in the DA matrix). Then, we would need something like 256 ILs in order to cover the whole blob mempool with sufficient redundancy.
- **Vertically sharded mempool**:
- *Availability check hard* ❌: IL proposers do not have strong availability guarantees, due to issue with multiple independent availability checks we discussed in the previous section, where in this case the relevant objects are blob txs in the mempool. All we can say is that, *for each unavailable blob transaction*, at most a small fraction of the nodes can be tricked into seeing it as available (same reasoning as [here](https://ethresear.ch/t/subnetdas-an-intermediate-das-approach/17169#global-safety-15)). Crucially, the set of tricked nodes can be different for each blob txs, so the set of nodes which is tricked on *at least one* blob tx can be very large. In particular, if enough blob txs are from adversarial senders, an IL proposer that chooses a large number of blob transaction has a high chance of choosing at least one unavailable one. *Due to this, we need to design our protocol in such a way that including some unavailable txs in an IL does not preclude the whole IL from being enforced.* In other words, IL enforcement has to be on a tx by tx basis. We discuss later how to do this.
- *Few ILs required to cover the mempool* ✅: here, we only need a single honest IL proposer to cover the whole mempool, because any mempool shard has all blob txs, though only a fraction of the associated blob data. Even with redundancy, we only need $r$ ILs instead of $rk$.
### IL satisfaction: (local) block builder
The block builder has to make a block which satisfies the constraints posed by *available* ILs. If a blob tx in an IL is unavailable, the block builder should of course not include that blob in its block, lest it be reorged. Once again, determining availability is problematic, at least for local block builders that do not or cannot download all blobs. There are two ways we could go about this:
1. **Block building requires a full mempool**: once we have ILs for all tx types, including blobs, local block building is mostly useful as a fallback to ensure network liveness regardless of what happens to professional builders (and other surrounding infrastructure like relays). Even at high blob counts, requiring a full mempool still leaves block building quite accessible, *as long as we have distributed block building infrastructure*. Essentially, the task of a (non-specialized) block builder would boil down to just listening to the *full* mempool and picking txs from it, especially any that show up in ILs, while the network helps with encoding and propagation. At 128 blobs/slot, following the mempool requires 1.3 MB/s, or ~10 Mbits/s. This is certainly more than we can expect all node operators to have or want to exclusively dedicate to their node, but seems like a fairly modest requirement for a fallback, likely giving us enough confidence that there would always be hundreds or even thousands or nodes that are able to step up if needed. In fact, even in normal conditions it might be feasible for many nodes to start listening to the full mempool just-in-time a few slots before proposing, if they have enough bandwidth to occasionally do so but do not wish to constantly allocate it all to their node.
2. **Provide block builders with an availability signal**: if we do want to support block building without full mempool participation, we need such block builders to determine availability. There is very little that such a local block builder can do *by itself*, without a DAS protocol that gives strong *individual availability guarantees*, for example through anonymous routing of queries. Absent that, we need to help local block builders somehow, for example through a committee vote that acts as an availability signal. As we'll see, this is also helpful for attesters.
### IL enforcement: attesters
If we want many blobs to be included, e.g. as much as the DA throughput, we obviously cannot gossip the ILs with full blobs, but rather only with either the blob transactions without blobs, or even just hashes. However, in order for an attester to decide whether satisfaction an IL should be enforced or not (i.e. whether to attest to a block proposal which does not satisfy it), it has to determine availability of the blob transactions it contains.
The obvious way to do so would be through some form of sampling, just like we do for the block. For example, an attester could sample each IL, coupling the availability of all transations that it contains. The sampling could even already have been done in the mempool, if the mempool sharding is done vertically.
However, when we have multiple ILs, we run into the by now well known issue of multiple independent availability checks: the amount of nodes/validators that can be tricked into thinking that *at least one* unavailable IL is available can be very large. If that were the case, many (even most) honest attesters could be tricked into thinking that the proposer is not satisfying some IL that should be satisfied, and therefore into voting against the proposed block. Once again, one way to get around this issue is to use a committee as an availability signal. We now discuss this approach.
## IL availability committee as distributed block building infrastructure
At a high level, we have 4 phases:
- **IL proposing:** blob ILs are sent, without containing blobs (e.g. they contain only tx hashes or blob txs without blobs)
- **Committee vote as availability signal**: a committee votes on the availability of the blobs associated to these ILs, each committee member according to its local mempool view (this automatically involves sampling in the vertically sharded mempool case, but it does not in the horizontally sharded mempool case).
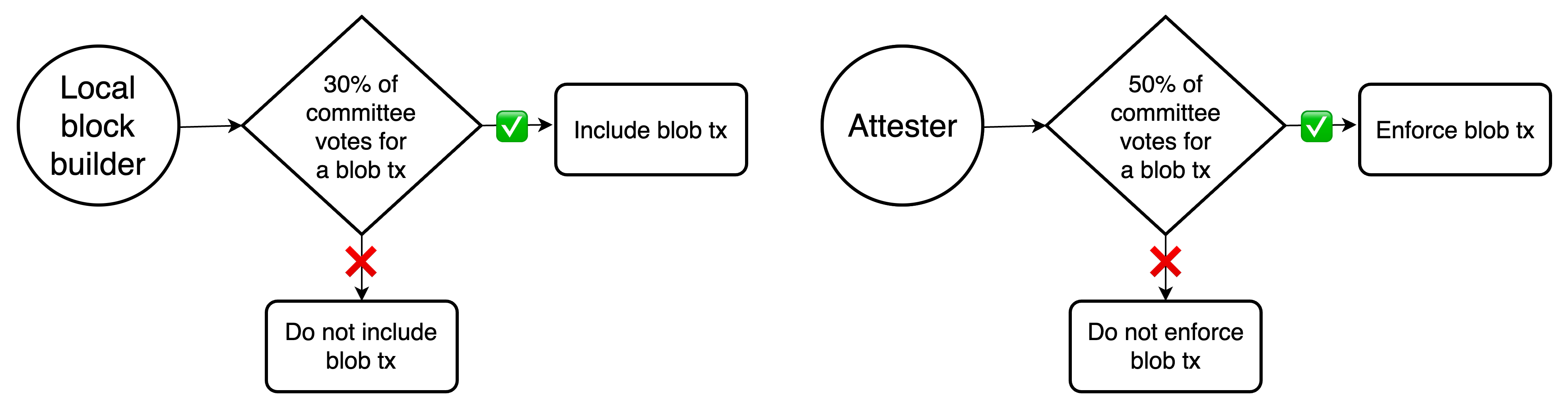
- **Block building**: someone building a payload for the next slot, either a local block builder or a PBS builder, has to decide which blob txs from ILs to include. A builder which downloads everything (as external builder would do, in their own interest) just includes all such available txs (if there's space to do so). A local block builder cannot determine availability by itself, and instead includes all txs which received at least 30% of the availability committee votes.
- **IL enforcement**: at some point, there is a round of voting on the payload, which, among other things, enforces the satisfaction of valid and available IL txs. To determine availability, voters rely on the previous votes by the availability committee, in particular enforcing satisfaction of IL txs which received at least 50% of the votes.
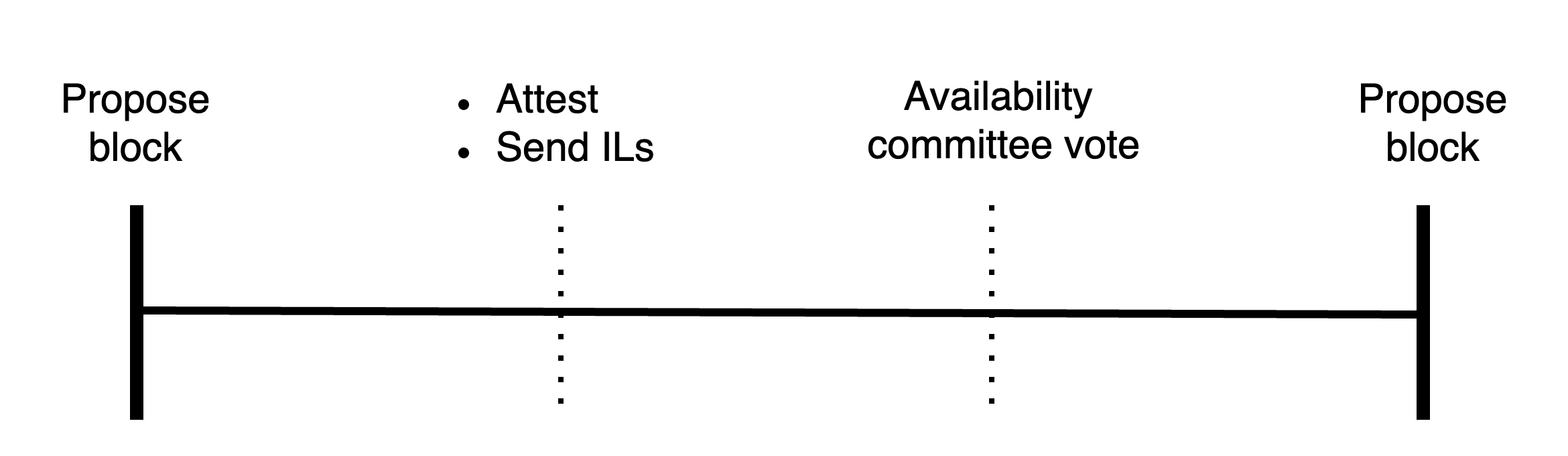
This is an example of what this could look like in today's slot structure:
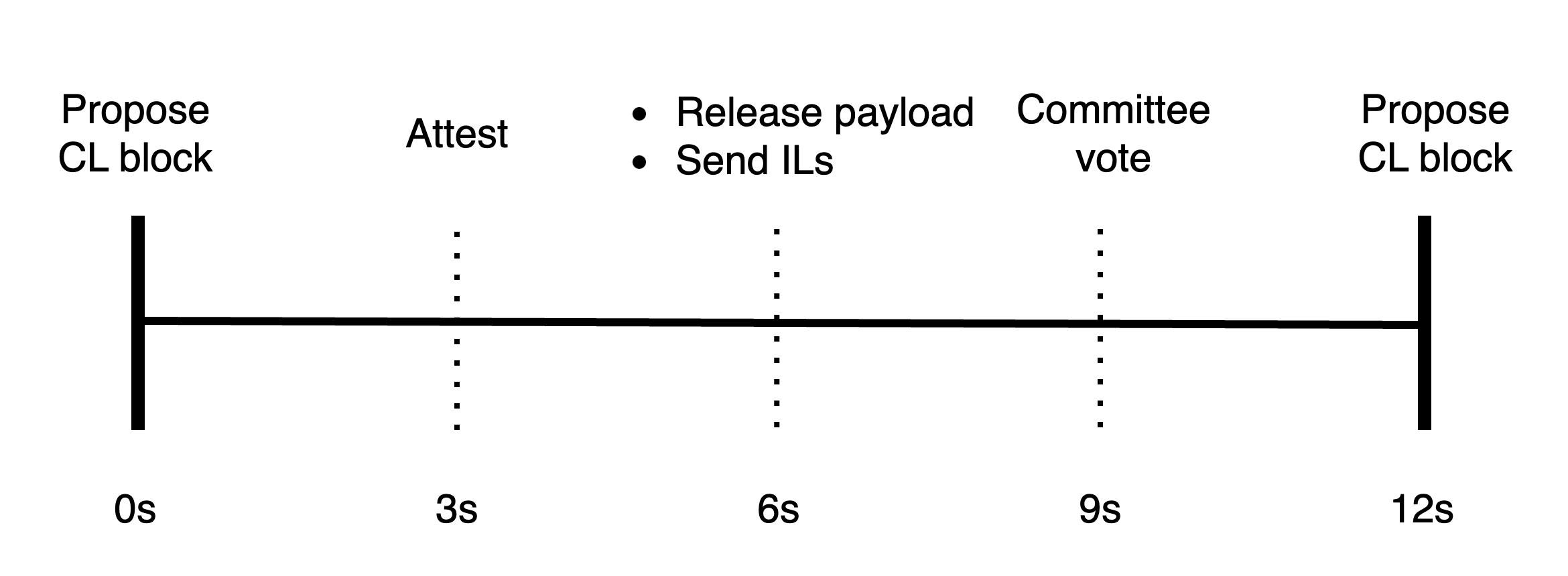
Whereas this could be how it would look like with an epbs slot structure, where "Committee vote" here refers to a committee that serves as both the epbs' payload timeliness committee (PTC) and the availability committee from this post (a single message will contain both votes).
### Concrete protocol assuming vertically sharded mempool
#### IL proposing
One possible advantage of a vertically sharded mempool is that we only need a few ILs to cover the whole mempool with redundancy. For this to be the case, we have to accept that IL proposers cannot fully determine the availability of the blob transactions they include (alternatively, though this is much more natural with a vertically sharded mempool, we could ask IL proposers to only include a few blob txs that they fully download, at the cost of needing many more ILs to cover the whole mempool). IL proposers will simply include any valid blob tx they have seen, as long as the blob chunks are available in the mempool shards they participate in. While this does not constitute a sufficient availability check for the reasons we already discussed, the rest of the protocol is structured so as to not require this.
### IL availability committee
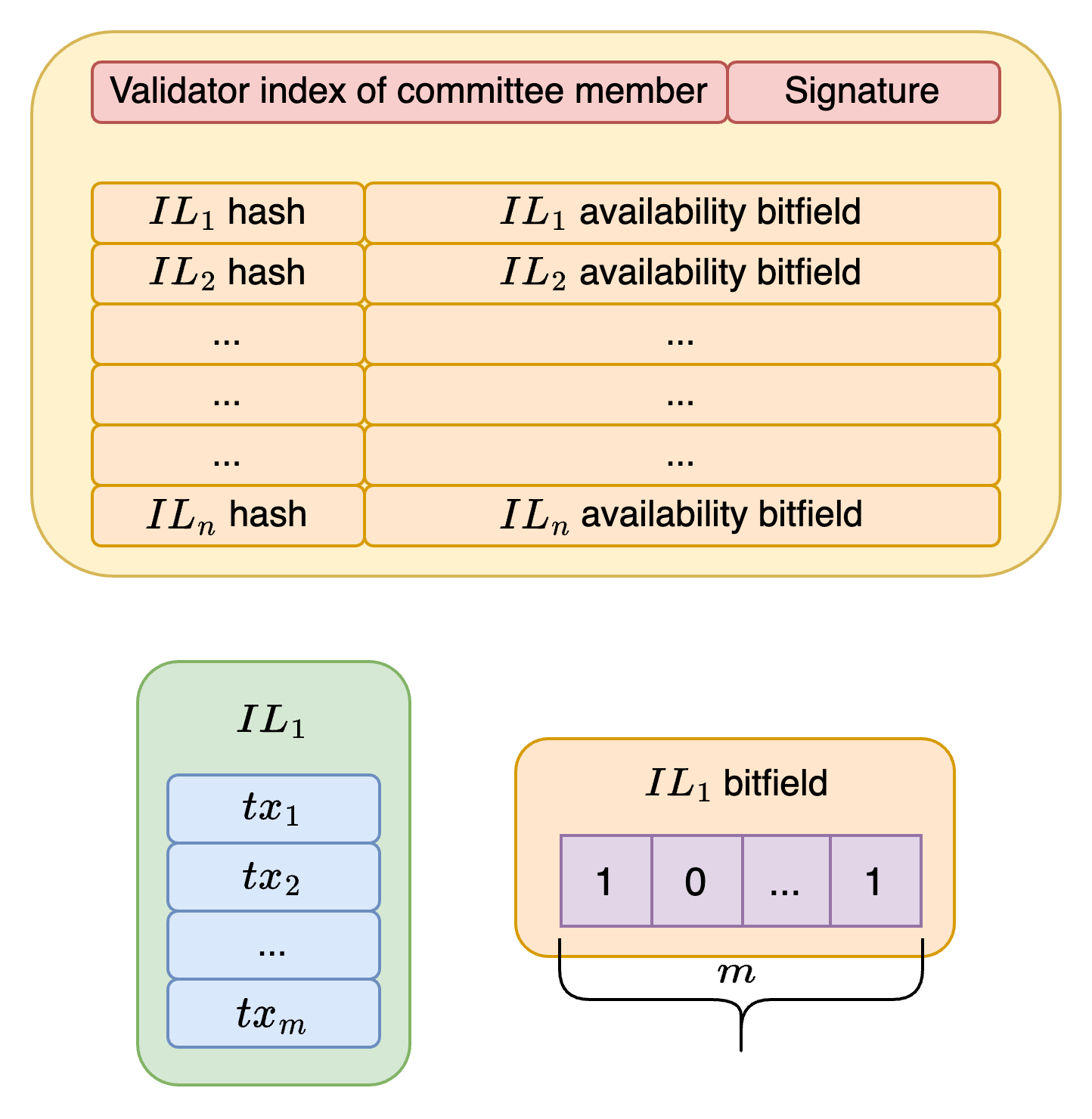
Given the lack of a full availability check from IL proposers, it would be undesirable if enforcement of IL satisfaction was done on an IL by IL basis, meaning that an IL would only be enforced if *all* blob txs in it were available, because then even a single unavailable blob would prevent a whole IL from being enforced. Therefore, we instead approach IL enforcement for blob txs on a tx by tx basis, just like we do for regular txs. To allow local block builders and attesters to deal with this, the committe has to provide an availability signal for each tx, which they do by adding a bitfield to each committee message.
Each vote from a member of the IL availability committee would then look like this, containing:
- a list of hashes for all ILs that were seen, *regardless of the availability of their transactions*
- a bitfield for each IL (hash), specifying the availability of each transaction in the IL, in the local view of the committee member.
*Note: for the purpose of showing up in such a vote, the only condition that an IL needs to satisfy is that the IL sender is indeed an IL proposer for this slot, however this is defined, e.g., via a VRF election like we do for aggregators or simply via RANDAO like we do for other committees. Of course the IL also needs to be received by the relevant committee member before it sends out its vote.*