# Sharded blob mempool and distributed block production
**TL;DR:**
Two scalable mempool designs have been discussed in the past: "horizontal" where blob transaction are transmitted as a whole with all data, but are split across several subnets for scaling; and "vertical", where nodes receive all transactions but blobs are split into erasure coded subnets (using the same sampling technique that is used to ensure included blob availability).
While the horizontal technique is clearly easier to implement, we found that in the light of distributed block building, the vertical technique is preferrable.
## Horizontally sharded mempool
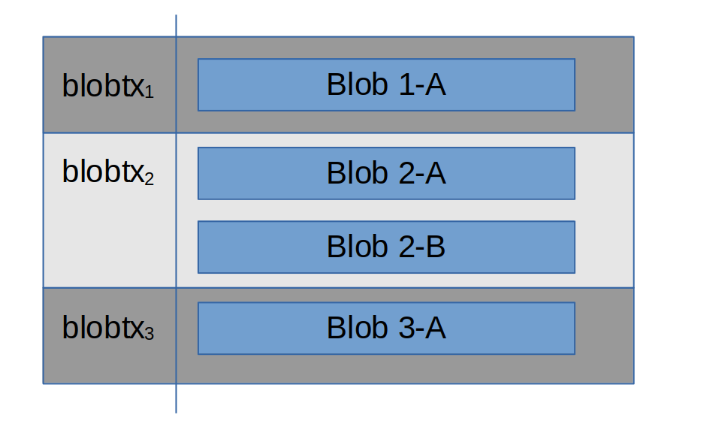
A horizontally sharded mempool is one where blob transactions are transmitted as a whole (including blob data), and transactions are split into several different mempools based on sender address.
Advantages:
* Very simple design
Disadvantages:
* No reliable way for local block builder to know if a transaction is available without downloading it; builder can ask peers but is trust based
## Vertically sharded mempool
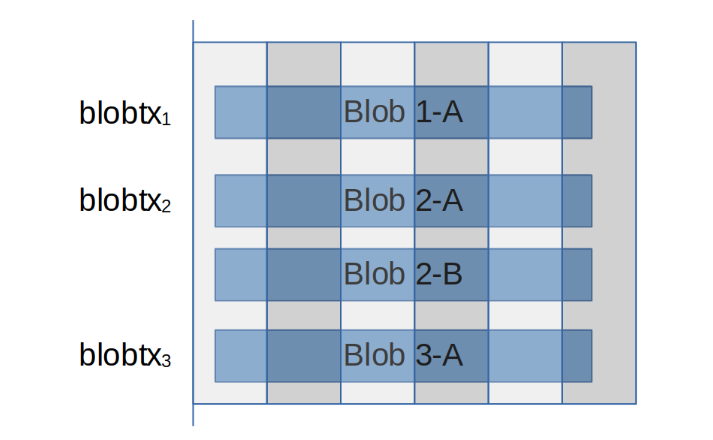
In a vertically sharded mempool, only the EL part of a transaction goes into the mempool (that stays as is), and blobs are split up into samples in the same way that the blob data will be samples as part of consensus blocks.
One of the bigger problems with creating this type of mempool is that samples and transactions have to be distributed separately. This creates a "chicken and egg" problem:
* If we allow transactions to be passed without the corresponding blob samples, it is a DOS vector on the tx pool
* If we allow samples to be passed without a corresponding transaction, then this is a DOS vector on the sample pool
* If we don't allow either of these, then no transaction will ever be propagated because no two nodes sampling requirements are identical
A solution to this is to limit blob transaction creation to certain addresses, for example:
* Addresses that have created a certain number of blob transactions over the last day or week
* Addresses that have burned a certain small amount of Ether (e.g. 0.01 ETH)
The second condition allows new addresses to enter the eligible pool.
We then require that both samples and transactions are signed by the sender address, which means they can be propagated independently (and any address seen to be spamming can be eliminated from the allowed sender list).
Advantages:
* More reliable blob availability information
* Data already split into samples, so distributed block building straightforward
Disadvantages:
* More complex to build
* Requires limitation to certain addresses
* Reliability of blob availability information is low; with many blobs this creates a chance of griefing attacks
* This is still better than in a horizontally sharded mempool where there is no availability information
## Inclusion lists
See note by @fradamt here: https://notes.ethereum.org/7EGS7DVtTAKnqlh9LDEWxQ?both
## Distributed block building
The basic principle of distributed block building is that a block builder
1. Uses some mechanism (probably relying on ILs, since these are most reliable) to determine availability of blob tx
2. Locally build an execution block with the available blob transactions
3. Propagate execution block, while other nodes will fill in the subnets with samples from their transaction mempool
There is a great advantage in using the vertically sharded construction as we can use the exact same subnets for sampling transactions and blocks. So nodes taking part in the mempool are likely to already have all the samples for any transaction from the mempool, which makes filling in samples very easy.
In the case of a horizontally sharded mempool, each node in a column subnet would only be able to find some of the corresponding samples in its mempool.