# Data Availability Sampling based on S/Kademlia
*Summary*: A data availability sampling networking design that is based on the S/Kademlia work which is a hardened version of Kademlia.
*Previous work*: https://notes.ethereum.org/@dankrad/Peer_DHT
# S/Kademlia
S/Kademlia ([Baumgart/Mies 2007](https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.68.4986&rep=rep1&type=pdf)) is an improvement on Kademlia based on three ideas:
1. In order to limit the number of nodes controlled by an attacker, add a PoW (proof of work) to node ID creation
2. Add a parallel lookup protocol: Each lookup is performed in parallel through $d$ (e.g. $d=8$) disjoint channels. As long as one of them only goes through honest nodes, the lookup is successful
3. Add a sibling broadcast list, a list of $\eta \cdot s$ nearest node maintainted by each node
This graph illustrates the robustness gained through parallel lookups:
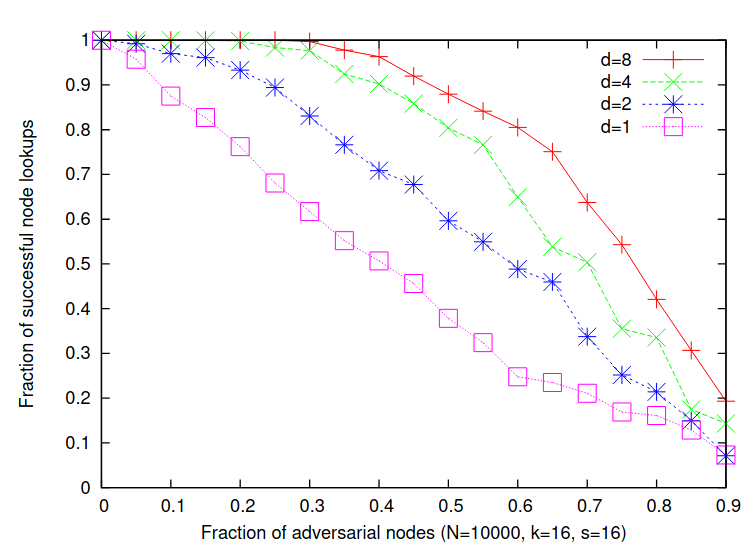
With $d=8$ parallel lookups, 90% of samples can still be retrieved even with 50% of nodes adversarial.
# S/Kademlia modifications
The Proof of Work idea is an interesting starting point, however in practice it is terrible: In order to get good resistance against an attacker willing to invest even a moderate amount of money into mining node IDs, the difficulty of creating a node ID would have to be set quite high, which in turn makes it expensive or impractical to run a node.
A more useful alternative is to use "proof of validator" to create node IDs. What we will essentially do is create two types of node IDs:
1. Normal node IDs, that have no sybil protection
2. Validator node IDs, that can only be obtained by nodes that run at least one validator clients. (Node IDs will be determined by validator keys and/or withdrawal addresses but can't be publicly linked to them)
Then each node will maintain *two separate* S/Kademlia tables (that include $k$-buckets and sibling lists):
1. One list that contains any node ID of type 1 and 2
2. A second list that contains only node IDs of type 2, i.e. only validators
The overhead of maintainting two instances of S/Kademlia is actually quite low because Kademlia can do most updates by using normal messages that come from DHT requests.
Key lookups are then performed according to S/Kademlia rules first using the primary table (that involves all nodes), and if this fails, using the secondary table (containing only validator nodes).
This DHT is then used as a key-value store for samples, with each sample stored at the address given by `hash(Commitment, row, column)`.
# Properties
* The primary DHT provides good performance in the "happy case" where there is no ongoing large-scale P2P network attack
* The secondary DHT serves as a backup that guarantees operation even if the permissionless network gets attacked, at the cost of potentially more restricted operations (e.g. only queries by validators satisfied if DOSed, see below under optimizations)
* There is a nice incentive alignment property in that the secondary validator network consists of nodes that have little incentive to DOS the network. Not providing samples stalls the chain, which is something that someone holding >50% of the stake can do anyway (at least in terms of finality).
* The Kademlia design very nicely scales with the number of nodes. Each sample only has to be stored by a constant number of nodes, e.g. 20. In this design with a backup secondary DHT, it would become 40 (20 for the primary and 20 for the secondary DHT). This scales much more nicely than subnets, where a fixed number of subnets would have to be built into the protocol and it can not automatically scale with the number of nodes
# Optimizations
* Kademlia implements a caching protocol where each value is additionally inserted into the closest node that did not return it on each lookup. This is not a desirable behaviour in our case, because samples are equally important so further replication of "more popular" samples is not beneficial to the network
* The node limitations in the secondary (validator-based) DHT mean that targeted subspace attacks become more attractive. This is why it is good to hash the sample keys, so that rows/columns can't be easily attacked. It may be advantageous to add backup lookup locations for each sample at `hash(Commitment, row, column, i)` for `i=0...5` to guard against subspace attacks
* A major downside of this construction is that many nodes will be contacted in a naïve implementation. E.g. if $d=8$ parallel lookups are used at a DHT depth of $4$, then a total of 32 nodes will be contacted for each sample, which is quite expensive. Two strategies can be employed to keep lookups at ~1 per requested sample:
* The $d$ disjoint lookups don't have to be done in parallel. Instead, we can start with just a single lookup, and only if it is not successful start the other disjoint ones (or even do an increasing strategy of 1, 3, 5)
* While looking up samples, we can simply cache all the nodes. In practice, the cost of this is low (E.g. storing nodeId, IP and port information for 100k nodes can be done in less than 10 MB) and the cost of outdated information is typically only one extra node contacted. In practice this cache will quickly converge to an almost complete node list so that most samples can be found in a single hop
* We want to optimize for robustness. If the impact of an attack can be minimized, then most likely the attack will never take place. The most vulnerable piece in this construction is the secondary DHT consisting of validator nodes. If the primary DHT fails, it needs to take over and provide the samples. To protect it further against DOS attacks, we can prioritize requests by other validator nodes, and only process a limited number of non-validator requests in the case of a DOS attack. This ensures that the validator network keeps working at all times, and high-value users such as exchanges can simply run a validator to be part of the network.
# Attacks
* The primary DHT suffers from all of Kademlia's problems as it does not have any limits on node ID generation. We can therefore assume that a serious attacker will disrupt it first and can do so with sufficient bandwidth and (less importantly) computing power
* However, in this case all nodes would rely on the secondary DHT, which is more difficult to disrupt. Here is a possible (non-exhaustive) list of attacks on this DHT:
* DOS attack
* Limited: Attack on a subrange. This can be mitigated by allowing backup location and adding tolerance for small numbers of missing samples
* Full scale: Same implications as a usual P2P attack
* "Sibling attack"
* Intuitively, it might sound expensive to attack the DHT as stake is required, but since typical nodes run on the order of 100 validators, it might be possible to control 50% of the table with as little as 1% of the stake.
* At current valuations, that's still >200 million, so likely this attack is still much more expensive than many DOS attacks that can probably be executed with <1M budget
* Withholding
* A large majority of nodes stops serving samples, thus making obtaining samples impossible. This is unlikely, as any stakeholder with sufficient stake would have more effective attacks on liveness already
* Targetted withholding
* Large staking pools can use their stake to withhold samples only from certain parties. If they manage to sufficiently disrupt the sampling process, those parties will see a chain that is available for most people as unavailable
* This can be used to grieve stakers (make them vote for minority chains)
* The resulting minority chains can also be passed off as the "real chain" to other parties and used for double spending attacks on users that do not check for high participation/finality
* Liveness
* Liveness attacks become possible given a majority of the stake. While this is already possible now with respect to finality, one of the ideas of the Gasper design is that a minority can continue building an available ledger. However, if the liveness-attacking majority attacks the secondary DHT, it may not be possible for this minority chain to include sharded data, since there would be no way of getting the samples
## Behaviour in case of forks
Assume that there is a minority fork due; example: Censoring supermajority, liveness-attack (on finality) by supermajority. The minority can keep building a chain, but the secondary DHT would now be essentially compromised.
This means that any UASF will have to include an update to the validator proof that excludes the "bad" validators, so that a new secondary DHT can be built around the minority fork. In practice, this also means a UASF will probably have to be executed in the case of a liveness attack.
# Possible further extensions
Clearly it is attractive to extend node ID generation to other networks, for example ENS domain holders, ETH addresses with a minimum balance, Proof of Humanity identities, or good P2P network participants (as determined by being peers of validator nodes). The beauty is that each of these could form its own independent "backup DHT" that can work independently, and if its Sybil mechanism fails it does not impact the other subnetworks. However, the downside of these is that these identities are not readily available to Ethereum nodes, so the UX of integrating them is very cumbersome and makes this less attractive in practice.