# Attacknet Introduction
## Introduction
Chaos testing is a disciplined approach to testing a system by proactively simulating and identifying failures. Ethereum networks in the wild are subject to a lot of real life variances that have historically been difficult to capture in local tests. We've worked with [Trail of Bits](https://www.trailofbits.com/) to create a tool that combines the two worlds together, allowing us to create local networks that can simulate real world chaos and failures. Examples would include adding network latency between nodes, killing nodes at random, filesystem errors being returned, etc
Such a tool has two major components: 1. A tool to deploy Ethereum networks and 2. A tool to orchestrate the chaos tests.
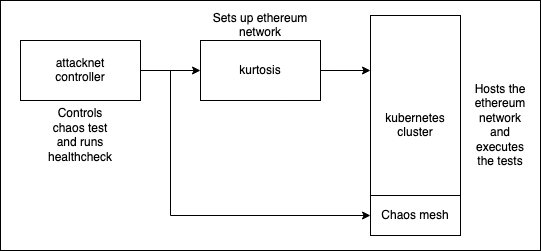
We have already solved 1. with [Kurtosis](https://github.com/kurtosis-tech/ethereum-package), it allows us to reliably deploy Ethereum networks (irrespective of which fork we're testing) to perform local docker based tests or remote Kubernetes based tests. To solve 2., we used a kubernetes testing framework called [Chaos Mesh](https://chaos-mesh.org/) which allows us to configure a host of failures that are then executed by the orchestrator. While these pieces of software give us the functionality we need, they don't provide the ease of use.
Introducing `Attacknet`, the missing piece was a software that can ingest a test definition and execute it for us. This would allow us to configure lists of cases we would like to see and have the execution of the test taken care of us. The software can also perform healthchecks and attempt to ascertain if a network was negatively affected by the chaos or not.
## Chaos types
`Attacknet` allows us to configure the following types of chaos for any duration we like and some also allow additional randomness (i.e, run fault only x% of time):
- Network: Network latency, jitter, packet drop, packet corruption and bandwidth limits
- Network split and re-joining
- Clock skews (i.e, NTP faults)
- CPU load
- RAM Load
- i/o: disk faults, disk access latency, i/o mistakes
- Service crashes (i.e, kills)
- WIP: Kernel faults
## Test Scenarios
Currently there are 3 factors we are playing with, i.e: Client combo in the network, Type of Chaos and Parameters of chaos. Here are some initial tests we planned:
| Test Number | Description | Chaos Type | Parameters | Analysis Objective | Notes |
|-------------|------------------------------------|-------------------------|----------------------------------------------------------|--------------------------------------------------------------|-------------------------------------------------------------------------------------------|
| 1 | Single EL type, One of each CL. | Network latency | Latency: 100ms, 500ms, 1000ms, 2000ms with 10% jitter | Analyze the number of missed slots and correlate with latency | Repeat with every EL |
| 2 | Single EL type, One of each CL. | Network packet drop | Packet Drop: 5%, 10%, 50%, 100% | Analyze the number of missed slots and correlate with packet drop | Repeat with every EL |
| 3 | Single EL type, One of each CL. | Clock skew | Clock Skew: 100ms, 500ms, 1000ms, 2000ms | Analyze the number of missed slots and correlate with clock skew | Repeat with every EL (EL shouldn’t matter in this test) |
| 4 | Single EL type, One of each CL. Apply partition to one CL at a time. | Network partition | N/A | Analyze if the CL can rejoin the network after the split is healed | Potentially use static peers to avoid downscoring issues. Restart of pods might be necessary. Repeat for every EL. |
| 5 | Single EL type, One of each CL. Split network into two halves. | Network partition | N/A | Analyze if the network can self heal | Use static peers to avoid downscoring issues. Repeat for every EL. |
We're trying to be vary of adding too many variables into the mix, we don't have good ways of knowing when a run "fails", so we're erring on the side of cation and building networks with more controlled changesets.
## Unknowns:
- What other scenarios are useful? What do client teams want to see?
- What data is useful to collect? Should we analyze missed slots or performance? What metrics do we focus on and how do we define healthy?
## Note:
Attacknet at this moment in time is closed source. We will be open sourcing it once we hit the Dencun fork on mainnet.