# EVM384 Update 4: The Final Exponentiation and the Pairing
[TOC]
## Introduction
This is a continuation of a series of updates on EVM384.
[Preview of EVM384](https://notes.ethereum.org/@axic/evm384-preview)
[Update 1: Can we do fast crypto in EVM?](https://notes.ethereum.org/@axic/evm384)
[Update 2: The Interfaces](https://notes.ethereum.org/@poemm/evm384-interface-update)
[Update 3: The Miller loop](https://notes.ethereum.org/@poemm/evm384-update3)
Feedback and discussion occurs on allcoredevs chat, allcoredevs calls, and on [this magicians thread](https://ethereum-magicians.org/t/evm384-feedback-and-discussion/4533).
In this update, we announce the completion of the final exponentiation implementation in EVM384. This is a major milestone for EVM384. Now that we have a full implementation of pairings in EVM384, we compare runtimes for a two pairing equation check against Rust and Wasm.
## Implementing Final Exponentiation
Final exponentiation is finished and successfully matches the output of [blst](https://github.com/supranational/blst). All code has been put into the [EVMcurves repository](https://github.com/poemm/evmcurves).
Final exponentiation is the second half of a pairing implementation. The first half is the Miller loop, which we completed in update 3. So now we have the full pairing implementation.
Now we discuss the developer experience of EVM384. Implementing cryptography in EVM384 is challenging. Currently, our toolchain uses two steps (python -> huff then huff -> evm). The Python is useful because we can easily write/modify/abstract algorithms and switch between interfaces. The huff code is useful for inspecting/debugging, and huff computes the jumpdests for us. We did not implement EVM384 in ethereumjs-vm so we couldn't use truffle/remix for debugging, or in hevm and kevm, both of which would provide nice debugging tools. Instead, we debugged by stepping through EVM execution opcode-by-opcode dumping memory and stack, a tedious process.
Final exponentiation had many unique challenges. Although we reused some operations from the Miller loop, many new operations had to be implemented. Unlike the Miller loop which is just a big loop that fits inside the 24kb bytecode limit, the final exponentiation is a long list of calculations, resulting in large bytecode, around 1.5MB. So great effort went into wrapping bytecode into "functions" which can be jumped to and from. These functions hard-code memory offsets for inputs/output, so require copying to/from buffers each time they are executed. Besides code size, another challenge is simultaneously optimizing for gas cost.
Some optimizations for gas cost and bytecode size were made, but others were omitted, in favor of simplicity.
## The Final Numbers, With No Scaling Factors
In earlier updates, we approximated by measuring partial implementations multiplied by scaling factors, which were [chosen](https://notes.ethereum.org/@axic/evm384#The-synthetic-loop) [heuristically](https://notes.ethereum.org/@poemm/evm384-update3#Miller-Loop-Synthetic-Benchmark). Now, we remove scaling factors, and measure the actual full implementation of a two pairing equation check. We present baseline numbers, noting that there is potential for optimizations in gas cost, especially in the parts with non-EVM384 opcodes.
___
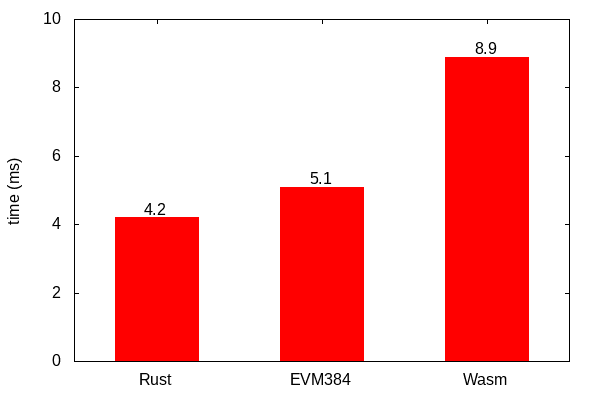
**Figure 1.** Runtimes for BLS12-381 two pairing equation check implemented in (i) Rust from EIP-1962, (ii) EVM384 [bytecode](https://gist.github.com/poemm/4ad9aa7e625d32883953f4170e106c10) executed in evmone, and (iii) Wasm from wasmcurves executed in Wabt with native bigint host functions.
___
Notes on apples-to-apples and runtimes: Runtimes may appear slow -- all benchmarks are run on an Azure VM (Xeon E5-2673 from 2016) which is slower than some of our laptops. Also, all implementations of `MULMODMONT384` are in plain source code, not hand-optimized assembly. (Aside: if you are worried about speed, we have measured 1.7 ms for the same EVM384 computation on a newer CPU and with `MULMODMONT384` in hand-optimized assembly.) We acknowledge that newer versions of the Rust code are more optimized, but we keep this original version to show how we approach our original target from earlier updates. We also acknowledge that the Wasm was off-the-shelf, and we suspect that we can speed it up for interpreters as well. (Actually, Wasm will be faster than similar EVM because Wasm has fewer runtime checks for things like the stack and control-flow.)
Notes about subgroup checks: None of the measurements above include subgroup checks. An advantage of EVM384 is that we can omit unnecessary subgroup checks. But for those curious, full subgroup checks in BLS12-381 implementations tend to add 15% to the total runtime, but, again, many use-cases can omit some subgroup checks.
## Conclusion
This concludes a major milestone for EVM384. We have shown that we can implement expensive crypto in EVM, and the runtimes are fast.
We welcome more implementations of cryptography using EVM384. We also welcome suggestions for better toolchains for writing such cryptography.
With this milestone, and the evidence it brings, we begin the process of writing an EIP for EVM384. We welcome feedback. Please share applications of EVM384 which we can include as motivations. For example, let us know if you plan to use EVM384 for things like algebraic hashing or STARK verification. Also, let us know if EVM768, which is like EVM384 but for 768-bit values, would be useful. Or any other useful EVM<bitlength>.
Our next update will give gas cost estimates for EVM384.