# Proposed DAS networking model
Since sometimes we want to store the data on-chain, but we cannot do it because the data is too large, we need to store its commitment on-chain instead and let the nodes verify that the data is available without actually downloading it.
Currently we have a design [[1]](https://notes.ethereum.org/@dankrad/new_sharding) [[2]](https://notes.ethereum.org/@vbuterin/proto_danksharding_faq) [[3]](https://github.com/ethereum/consensus-specs/tree/dev/specs/sharding) that is robust but we abstracted away how the network works by just assuming that we can somehow (1) publish the samples and (2) fetch the samples.
This proposal will outline how those two operations work.
## Observation
Initially, we try to utilize the DHT to publish the samples and fetch the samples, but it turns out it's susceptible to many kinds of attacks, such as the eclipse attacks or other DoS/spamming attacks.
The situation of DAS is quite unique and different from those of other systems (like IPFS). You can notice that, from the [Danksharding](https://notes.ethereum.org/@dankrad/new_sharding) design, the rate of publishing the samples to the network is predictable and nearly constant (128MB/block plus some occasional publish of reconstructed samples) which is different from the use case of IPFS whose the publishing rate is unpredictable.
We will use this observation to design the networking model proposed in this proposal.
## Operations
We can divide the networking function of DAS into three operations:
1. Disseminate the whole matrix of the data to the network (512 * 512 samples in total per block)
2. Query for a random sample from the network.
3. Disseminate the missing samples after the reconstruction.
## The Network
Each sample is hashed into a 256-bit id: `H(fork_digest, randao_mix, data_id, sample_index)`
* `fork_digest` (`f`) - Bytes4, fork digest to separate networks.
* `randao_mix` (`r`) - Bytes32, is randomness picked based on the sample time: this prevents mining of node identities close to a specific sample far in the future.
* `data_id` (`x`) - Bytes48, is the KZG commitment of the data: samples are unique to the data they are part of.
* `sample_index` (`i`) - uint64, identifies the sample.
The definition is copied from the one of [protolambda](https://github.com/protolambda/dv5das).
Assume that we have a set of nodes in the network each of which has a 256-bit node id. They also publish their ENRs in the Discv5 DHT.
There are 256 gossip topics/subnets used to disseminate the samples.

The entire id space is divided into 256 subspaces each of which corresponds to a gossip subnet.
Each node is respossible to store all the samples whose id is in the covered space, that is `xor(nodeId, sampleId) < 2^248`.
Each node must subscribe to a single subnet which cover all the samples it is responsible to. That is, the subnet of `nodeId >> 8`.
In addition to forming a network in each subnet, we require that all nodes in each subnet must connect to each other.
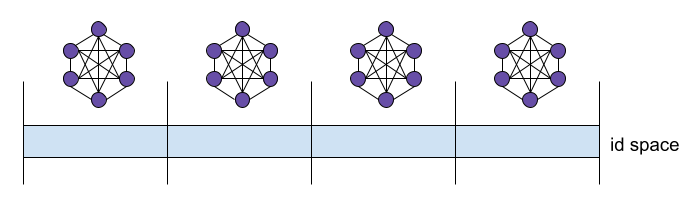
This results to a clique in each subnet. This ensures that, **if there is at least one honest node in the subnet, you are always connected to an honest node and you will not be eclipsed out**.
Invariants: Since all the subnets are cliques, we claim that, at any time,
1. If any *honest* node in the clique has some sample, all the *honest* nodes in the clique also have such sample.
2. If any *honest* node in the clique doesn't have some sample, all the *honest* nodes in the clique also don't have such sample.
In other words, all the honest nodes in the clique will always have the same set of samples.
## Disseminate the whole matrix
After the block builder successfully bids the block, it will disseminate the whole matrix (512 * 512 samples = 128MB) to the network.
The block builder does this by following the steps below:
1. Compute the ids of the samples to be published.
2. Use Discv5 to find a node in each of the subnets to which the builder needs to publish the samples.
3. Publish the samples in the corresponding subnets.
If the node found from Discv5 is honest, all the nodes in the subnet will certainly get the sample (because it's a clique) and the invariants are satisfied.
If it's unhonest and doesn't forward the sample to any honest node, no honest node will have the sample. The invariants are satisfied.
If it's unhonest and doest forward the sample to at least one honest node, all the honest nodes will have the sample because such node will further forward it to the others. The invariants are satisfied.
The invariants also give a nice mechanism to detect the adversary nodes. If the builder figures out later that some honest nodes in the subnet don't get the sample, the builder will know that the node to which it forwards the sample earlier is adversarial. (TODO: We will probably need to find a way to penalize the node)
The step 2 can be slow but that's fine because the number of samples is a lot larger than the number of subnets. The builder probably needs to find the nodes in all subnets in advance anyway.
The block builder has to do this before the timeout is reached (let's denote the timeout by `DISSEMINATE_TIMEOUT`). If the timeout is 2 seconds, it must have the bandwidth of at least 64MB/s which is fine because we assume that the block builder has a lot of bandwidth.
_PS. The block builder may choose to disseminate the samples to more nodes in the subnet to increase the chance that at least one honest node will receive the sample, but it will requires more bandwidth to do so. Or if they don't want to have more bandwidth requirement, they may choose to gossip the IHAVE message instead of sending the sample._

#### Forwarding in the subnets
In order to prevent the DoS/spamming attacks, the following validations must pass before forwarding the samples in the subnets.
* _[REJECT]_ The validator defined by the builder in the sample exists and is slashable.
* _[REJECT]_ The sample signature is valid for the builder.
* _[REJECT]_ The sample is proposed by the expected builder for the sample's slot.
* _[REJECT]_ The sample is for the correct subnet.
* _[REJECT]_ The proof in the sample is invalid.
* _[REJECT]_ The sample does not contain any point `x >= BLS_MODULUS`.
* _[IGNORE]_ The sample is new enough to still be processed.
* _[IGNORE]_ The sample slot is not too far in the future.
* _[IGNORE]_ The sample is the first sample with valid signature received for the slot and `sample_index` combination.
## Disseminate the reconstructed samples
If some samples are missing, anyone can reconstruct the samples and disseminate them.
Disseminating the reconstructed samples has no time limit so **it's okay to be slow**.
The steps are similar to the one of disseminating the whole matrix:
1. Compute the ids of the samples.
2. Use Discv5 to find a node in the subnets.
3. Publish the samples in the corresponding subnets.
#### Forwarding in the subnets
This case is quite different from the one in disseminting the whole matrix because the disseminated sample may be the old sample.
* _[REJECT]_ The sample is for the correct subnet.
* _[REJECT]_ The proof in the sample is invalid.
* _[REJECT]_ The sample does not contain any point `x >= BLS_MODULUS`.
* _[IGNORE]_ The sample slot is old enough.
* _[REJECT]_ No sample that has the same slot, the same `sample_index`, and the different data is in the storage.
* _[IGNORE]_ No sample that has the same slot, the same `sample_index`, and the same data is in the storage.
The last two validations are the ones we get from the invariants. If the sample is not really missing, there is no need to forward it.
## Query random samples
Given a `sample_index`, in order to query the sample at that index, you need to know some honest nodes in the corresponding subnet. When you know the nodes, you can just query the sample.
You need to use Discv5 to find the nodes in the subnet. If the found nodes are honest, it's good. If they are not, you will probably not get the sample.
**Property**: Note that, when you are connected to an honest node, due to the invariants if you can get a sample, it means it's available. If you can't, it means it's unavailable. There is no need to try to connect to other nodes to try to get it.
Querying the Discv5 DHT can be slow. Instead of randomizing the `sample_index` from the entire matrix, the verifier should randomize the `sample_index` only from the subset of the matrix which is more efficient for the verifier.
The subset is determined by the fixed subnets in which the verifier knows some honest nodes.
When the verifier becomes online, they will choose some random subnets (denoted by `subnets`) and use Discv5 to discover the nodes in the subnets as many as possible. Obviously with a high chance, they will know at least one honest node.
They will remember those nodes forever and update the nodes by receiving the IMALIVE messages which will be described later.
When the verifier wants to verify the matrix of the slot is available, they will do the following steps:
1. Given `fork_digest`, `randao_mix` and `data_id`, iterate through all the `sample_index` in the entire matrix (512 * 512 iterations in total) and see which one corresponds to a subnet in `subnets`. The qualified samples form the subset mentioned earlier. Let's denote it by `samples`.
2. Get some random samples from `samples`. (Probably 32 samples)
3. For each random sample, query the nodes in the subnet corresponding to the sample in a **random order** until it finds the sample.
4. If all (or nearly all) the samples are found, the verifier decides that the whole matrix is available.
At step 3, you can see that you may not get the sample from the first node queried in the subnet. Let's say you can't get from the first node but you can from the second node.
There are two possibilities here.
1. The first node is unhonest because it doesn't return the sample.
2. The second node is unhoest because it has a sample but didn't forward it to the others in the subnet.
If it's the second case, the verifier can help the subnet by disseminating the sample to the first node and that node will forward it to the entire subnet.
Please also note that `subnets` is used across slots and will not change.
## Inside the Clique
In order for all the nodes in the subnet to learn new nodes or learn the leaving nodes, every node in the subnet need to publish the IMALIVE message regularly to the subnet. (probably every 3 or 5 seconds, the exact number is TBD)
If the node doesn't receive the IMALIVE message from a node for some period, it can assume that the node has left the clique.
If the node receives the IMALIVE message from a new node, they can connect to each other to make the subnet still a clique.
#### Joining the subnet
When a node wants to join the subnet, it will
1. Use Discv5 to find as many nodes in the subnet as possible.
2. Connect to the found nodes.
3. Use `fork_digest`, `randao_mix` and `data_id` of all the historical blocks that are not older than 1 month and all the `sample_index` to find which samples it should have.
4. Ask the found nodes for the samples.
5. Verify all the samples.
6. Publish the ENR to the Discv5 DHT.
7. Start sending IMALIVE message.
The joining node has a high chance to find an honest node from Discv5, in which case the joining node can have all the samples from the honest nodes.
However, there is still a chance that it cannot find an honest node at all. In that case, we will classify the joining node as an unhonest node (just to make the invariants statisfied).
You can see that the unhonest nodes may send the joining node some samples that the honest nodes don't have. In that case, the joining nodes will have more samples than the honest nodes which make the invariants unsatisfied. Currently, we assume that the unhonest nodes will not do that. (TODO: This can be solved by compairing the commitments of all the stored samples to each other and somehow self-heal that?)
#### Leaving the subnet
Just leave (or probably publish a new kind of message ILEAVE, the decision is TBD)
#### GossipSub

Not every link in the clique is used to forward the samples or other topic messages. Some are used to send the samples (solid links in the figure), but some are used only to gossip that the sender has the samples (dashed links in the figure). See more detail [here](https://docs.libp2p.io/concepts/publish-subscribe/).
So the bandwidth used to send the samples by each node doesn't increase propotionally to the number of nodes in the clique. We make the subnet a clique only to make sure that each node can send the samples to other nodes without censorship.
## Resource usage
Let's assume that `DISSEMINATE_TIMEOUT` is 2 seconds for an easy analysis. The real number is TBD.
The block bulider will need **64MB/s** (128MB/`DISSEMINATE_TIMEOUT`) as mentioned earlier to send 128MB to the network in 2 seconds.
Each node in the network will be expected to receive 128MB/256 = 512KB per block. That is **256KB/s** (128MB/`DISSEMINATE_TIMEOUT`) for downstream link and also **256KB/s** upstream link to forward the samples to other nodes in the subnet.
If the nodes are expected to store all the samples in the last month, they will need around (512KB * (60 * 60 * 24 * 30s) / 12s) = **110GB of storage** which I think is fine because running a beacon node usually requires 100-200GB already.
## Scalability
Currently, there are around [5,000](https://ethernodes.org/) beacon nodes in Discv5 so there will be around 20 nodes in each subnet.
If the network grows to 25,000 nodes, it will probably make sense to increase the subnets to 512 subnets which will decrease the bandwidth and storage requirement.
But if it grows and we don't change the number of subnets, the network is still fine because the bandwith and storage requirement doesn't grow with the number of nodes. We will just not fully utilize the resource provided by the network.
If the network shrinks, it's also fine if there are still a few nodes in each subnet. Since we make each subnet a clique, it's hard to have a network partition.
## Open questions
1. If the network grows, can we make the network scale automatically?