# Eth2 shard chain simplification proposal
### TLDR: Key Points
* There is no longer (much of) a concept of a persistent shard chain. Instead, every shard block is directly a crosslink. Proposer proposes, crosslink committee approves, done.
* Shard count is reduced from 1024 to 64. Shard block size is increased from (16 target, 64 cap) to (128 target, 512 cap) kB. Total capacity is 1.3-2.7 MB/s depending on slot time. Shard count and block size can be increased over time if desired, eg. eventually going up to 1024 shards / 1 MB blocks after 10 years.
* Many simplifications at L1 and L2: (i) much less shard chain logic required, (ii) no need for layer-2 cross-shard acceleration as "native" cross-shard comms happen in 1 slot, (iii) no need for DEX to facilitate paying txfees across shards, (iv) EEs can become much simpler, (v) no need to mix serialization and hashing anymore
* Main drawbacks: (i) more beacon chain overhead, (ii) longer shard block times, (iii) higher "burst" bandwidth reqs but lower "average" bandwidth reqs
### Preamble / rationale
Much of the complexity in the current eth2 architecture, specifically at the fee market level, stems from the need to create layer-2 workarounds against a major failing of the eth2 base layer: while block times _within_ a shard are very low (3-6s), base-layer communication times _between_ shards are very high, at 1-16 epochs and even more if >1/3 go offline. This all but necessitates "optimistic" workarounds: a subsystem within one shard "pretends" to know the state roots of other shards ahead of time, learning them through some medium-security mechanism like a light client, and calculates its own state by processing transactions using these likely-but-not-certain state roots. Some time later, a "rear-guard" process goes through all the shards, checks which computations used "correct" info about other shards' states, and throws out all computations that did not.
This procedure is problematic because while it can effectively simulate ultra-fast communication times in many cases, complexities arise from the gap between "optimistic" ETH and "real" ETH. Specifically, block proposers cannot be reasonably expected to "know" about optimistic ETH, and so if a user on shard A sends ETH to a user on shard B, there is a time delay until the user on shard B has protocol-layer ETH, which is the only thing that can be used to send transaction fees. Getting around this requires either decentralized exchanges (with their own complexities and inefficiencies) or relayer markets (which raise perennial concerns about monopoly relayers censoring users).
In addition, the current crosslinking mechanism adds a large amount of complexity, effectively requiring an entire suite of blockchain logic, including reward and penalty calculations, a separate state to store pending in-shard rewards, and a fork choice rule, to be put into shard chains as part of Phase 1. This document proposes a radical alternative that removes all of these issues, leading to ETH2 being usable sooner and with fewer risks, with some tradeoffs that are documented.
### Details
We reduce `SHARD_COUNT` from 1024 to 64, and increase the maximum number of shards per slot from 16 to 64. This means that the "optimal" workflow is now that during every beacon chain block, there is a crosslink published for every shard (for clarity, let us retire the word "crosslink" as we're not "linking" to a shard chain and use the word "shard block" directly).
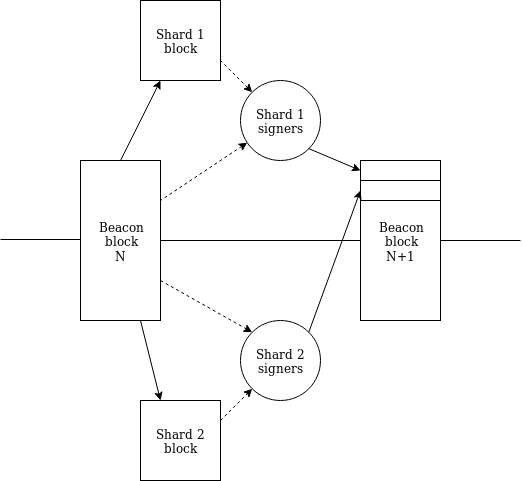
Notice a key detail: there is now a pathway by which a slot-N+1 block of _any_ shard is aware of _all_ slot-N blocks of _all_ shards . Hence, we now have first-class single-slot cross-shard communication (through Merkle receipts).
<br>
<center>
<img src="https://storage.googleapis.com/ethereum-hackmd/upload_85e9dfa9931179f4d35b4d40280f716c.png" />
<br><br>
<i>Status quo (approximate)</i></center>
<br>
<center>
<img src=https://storage.googleapis.com/ethereum-hackmd/upload_8bbf48bf0f184a5fabcc21338c536b1d.png />
<br><br>
<i>Proposal</i></center>
<br>
We change the structure of what attestations link to: instead of containing a "crosslink" including a "data root" representing many shard blocks in some complex serialized form, it just includes a data root representing the contents of a single block, whose contents are decided entirely by a "proposer". A shard block would also include a signature from the proposer. Proposers are calculated using the same persistent-committee-based algorithm as before; this is to encourage p2p network stability. If there is no proposal available, crosslink committee members can vote for an empty "zero proposal".
In the state, we store a map `latest_shard_blocks: shard -> (block_hash, slot)` as before, except storing the slot instead of the epoch. In the "optimistic case", we expect this map to update every slot.
Define `online_validators` as the subset of active validators that have had an attestation included in at least 1 of the last 8 epochs. The map is updated if 2/3 of `online_validators` (by total balance) agree on the same new block for a given shard.
If the current slot is `n` but for a given shard `i`, `latest_shard_blocks[i].slot < n-1` (ie. the previous slot had a skipped block for that shard), we require attestations for that shard to provide data roots for _all_ slots in the range `[latest_shard_blocks[i].slot + 1....min(latest_shard_blocks[i].slot + 8, n-1)]`.

Shard blocks are still required to point to a "previous shard block" and we still enforce consistency, so the protocol requires such multi-slot attestations to be consistent. We expect committees to use the following "fork choice rule":
* For each valid+available shard block `B` (the block's ancestors must also be valid+available), compute the total weight of validators whose most recent messages support `B` or a descendant of `B`; call this the "score" of `B`. Empty shard blocks can also have scores.
* Pick the shard block for `latest_shard_blocks[i].slot + 1` with the highest score
* Pick the shard block for `latest_shard_blocks[i].slot + k` for `k > 1` with the highest score, only considering blocks whose previous-block pointer points to the choice already made for `latest_shard_blocks[i].slot + (k-1)`
### Recap
The process between publication of beacon block N and beacon block N+1 would look as follows:
1. Beacon block N is published
2. For any given shard `i`, the proposer of shard `i` proposes a shard block. The execution in this block can see the root of beacon block N and older blocks (if desired, we can reduce visibility to just block N-1 and older; this would allow beacon blocks and shard blocks to be proposed in parallel).
3. Attesters mapped to shard `i` make attestations, which include opinions about the slot N beacon block and the slot N shard block on shard `i` (and in exceptional cases also older shard blocks on shard `i`)
4. Beacon block N+1 is published, which includes these attestations for all shards. The state transition function of block N+1 processes these attestations, and updates the "latest states" of all shards.
### Overhead analysis
Note that no actors need to constantly be actively downloading shard block data. Instead, proposers only need to upload up to 512 kB in < 3 seconds when publishing their proposal (assuming 4m validators, each proposer will on average do this once every 128k slots), and then committee members only need to download up to 512 kB in < 3 seconds to validate a proposal (each validator will be called upon to do this once per epoch, as we are retaining the property that each validator is assigned to a particular crosslink in a particular slot in any given epoch).
Note that this is lower than the current long-run per-validator load, which is ~2MB per epoch. However, the "burst" load is higher: up to 512 kB in < 3 seconds instead of up to 64 kB in < 3 seconds.
The beacon chain data load from attestations changes as follows.
* Each **attestation** has 224 bytes base overhead (128 AttestationData, 96 signature), plus between 32 bytes (normal case) and 256 bytes (worst case) for an attester bitfield. That's 256-480 bytes per attestation. A block would have maximum 256 attestations and average ~128 (guess) so that's 122880 bytes worst-case, 32768 bytes average case.
* Each **shard state update** has: (i) block body chunk roots, one root per 128 kB block data or part thereof, so ~48 bytes average and 128 bytes max, (ii) shard state roots, 128 bytes, (iii) block body length, 8 bytes, (iv) custody bits, 32 bytes (normal case) to 256 bytes (worst case). That's 216 bytes average and 520 bytes worst-case. A block can have a maximum of 256 shard state updates, average 64. That's 133120 bytes worst-case, 13824 average case.
For efficiency reasons, we only include shard state update data in the winning attestation in a block; all other attestations can include only the hash instead. This allows us to considerably save on data.
Note also that attestation aggregation will have an overhead of 65536 * 300 / 64 = 307200 bytes per slot in each shard. This presents a natural floor to the system requirements for running a node, and so is little value in making block data _much_ smaller than this.
Computationally speaking, the only significant added expenditure is more pairings (more Miller loops, more specifically), going from a maximum of 128 to a maximum of 192 per block; this would increase block processing times by ~200ms.
### The shard "basic operating system"
Every shard has a state, which is a mapping `ExecEnvID -> (state_hash, balance)`. A shard block is split into a set of chunks, where each chunk specifies an execution environment. The execution of a chunk takes as input the state root and the contents of the chunk (ie. a portion of the shard block data) and outputs a list of `[shard, EE_id, value, msg_hash]` tuples, maximum one `EE_id` per shard (we add two "virtual" shards: transfers to shard -1 represent validator deposits to the beacon chain, and transfers to shard -2 pay a fee to the proposal). We also subtract the sum of the `value`'s from that EE's balance.
In the shard block header, we put a "receipt root", which contains a mapping `shard -> [[EE_id, value, msg_hash]...]` (maximum 8 elements per shard; note that in a world where most cross-shard EE transfers are send-to-same-EE even fewer should suffice).
A shard block on shard `i` is required to contain a Merkle branch of the receipt for shard `j` of each other shard, rooted in the other shard's receipt root (any shard `i` is aware of the receipt root of any shard `j`). The value received is assigned to its EE, and the `msg_hash` is made accessible to EE execution.

This allows instant transfer of ETH between EEs between shards, with an overhead of (32 * log(64) + 48) * 64 = 15360 bytes per block. The `msg_hash` can be used to reduce the size of witnesses for passing around cross-shard information along with the ETH transfers, so in a highly active system that 15360 bytes will often be data that would have been needed anyway.
### Main benefit: easier fee markets
We can modify the execution environment system as follows. Each shard would have a state, which would contain the state roots and the balances of execution environments. Execution environments would have the ability to send receipts, which send coins directly to the same execution environment on other shards. This would be done using a Merkle branch processing mechanism, with every shard EE state storing a nonce for every other shard as replay protection. EEs could also directly pay a fee to the block proposer.
This provides enough functionality to allow EEs to be built on top that allow users to hold coins on shards, use those coins to send transaction fees, and move those coins between shards as easily as they move them within a shard, removing the pressing need for relayer markets, or for EEs to carry the burden of implementing optimistic cross-shard state.
### Full and reduced attestations
For efficiency reasons we also make the following optimization. An attestation referencing slot `n` can be included in slot `n+1` in its full form, as before. However, if such an attestation is included in a later slot, it must be included in a "reduced form" that only contains the beacon block (head, target, source), NOT any crosslink data.
This both cuts down on data, and importantly by forcing "old attestations" to hold the same data it cuts down on the number of pairings needed to verify the attestations: in most cases, all old attestations from the same slot can be verified with a single pairing. If the chain does not fork, the number of pairings needed to verify old attestations is limited to twice the epoch length in the worst case. If the chain does fork, then the ability to include all attestations becomes conditional on a higher percentage of proposers (eg. 1/32 instead of 1/64) being honest and including the attestation earlier.
### Preserving light client guarantees
Every day we randomly select a committee of ~256 validators that can sign off on every block, and whose signatures can be included to be rewarded in block `n+1`. This is done to allow low-power light clients to operate.
### Aside: data availability roots
Making a data availability proof for 128 kB is excessive and provides little value. Hence, what instead makes sense is to require a block to provide a root of the concatenation of _all_ shard block data that the block accepted, combined together (perhaps the shad block data roots would be lists of roots each representing 64 kB to make concatenation easier). A single data availability root could then be made based on this data (that's 8 MB average, 32 MB worst case). Note this creating these roots would likely take considerably longer than one slot, so it may be best for checking availability of data older than one epoch (ie. sampling from these data availability roots would be an additional "finality check").
### List of other possible extensions
* Shard blocks for slot `n` must reference the beacon chain block at slot `n-1`, not slot `n`. This would allow the per-slot cycle to happen in parallel rather than in series, allowing the slot time to be reduced, at the cost of increasing cross-shard communication time from 1 slot to 2 slots
* If a block proposer wants to make a block larger than 64 kB (note: the target is 128 kB), they need to first make 64 kB of data, then get the crosslink committee to sign off on it; then, they could add another 64 kB that references the first signature, and so on. This would encourage block producers to publish partially completed versions of their blocks once every couple of seconds, creating a kind of pre-confirmation.
* Speed up development of secret leader election (for simplicity, even a ring-signature-based version where the anonymity set is ~8-16 would be helpful)
* Instead of the "mandatory inclusion" mechanism proposed here, we could have a simpler mechanism where each shard maintains an "inbound nonce" and "outbound nonce" for each other shard (that's 8 * 64 * 2 = 1024 bytes of state), and receipts made by one shard would need to be included manually and can be processed by the recipient shard sequentially. Receipt generation would be limited to a small number of receipts per destination shard per block to ensure that a shard can process all incoming receipts even if all shards are sending to it.