# A step-by-step roadmap for scaling rollups with calldata expansion and sharding
[Rollups](https://vitalik.ca/general/2021/01/05/rollup.html) are in the short and medium term, and possibly the long term, the only trustless scaling solution for Ethereum. Transaction fees on L1 have been very high for months and there is greater urgency in doing anything required to help facilitate an ecosystem-wide move to rollups. Rollups are already significantly reducing fees for many Ethereum users: [l2fees.info](https://l2fees.info/) frequently shows Optimism and Arbitrum providing fees that are ~3-8x lower than the Ethereum base layer itself, and ZK rollups, which have better data compression and can avoid including signatures, have fees ~40-100x lower than the base layer.
However, even these fees are too expensive for many users. It has been understood [for a long time](https://ethereum-magicians.org/t/a-rollup-centric-ethereum-roadmap/4698) that the solution to the long-term inadequacy of rollups in their present form is [data sharding](https://github.com/ethereum/consensus-specs#sharding), which would add ~1-2 MB/sec of dedicated data space for rollups to the chain. **This document describes a pragmatic path toward that solution, which unlocks data space for rollups as quickly as possible and adds additional space and security over time.**
### Step 1: tx calldata expansion
Existing rollups today use transaction calldata. Therefore, if we want to give a short-term boost to rollup capacity and reduce costs without requiring the rollup teams to do any extra work, we should just decrease the cost of transaction calldata. Average block sizes today [are far away](https://ethereum-magicians.org/t/eip-2028-transaction-data-gas-cost-reduction/3280/35) from sizes that would threaten the stability of the network, so it is possible to do this safely, though it may require some additional logic to prevent very unsafe edge cases.
See: [EIP 4488](https://github.com/ethereum/EIPs/pull/4488), or the alternative (simpler but milder in effect) [EIP 4490](https://github.com/ethereum/EIPs/pull/4490).
EIP 4488 should increase data space available to rollups to a theoretical max of **~1 MB per slot** and decrease costs for rollups by ~5x. It can be implemented far more quickly than the later steps.
### Step 2: a few shards
At the same time, we can start doing the work to roll out "proper" sharding. Implementing proper sharding in its complete form would take a long time, but what we _can_ do is implement it piece by piece, and get benefits out of each piece. The first natural piece to implement is the "business logic" of the [sharding spec](https://github.com/ethereum/consensus-specs/blob/dev/specs/sharding/beacon-chain.md), but avoiding most of the difficulties around networking by keeping the initial number of shards very low (eg. 4). Each shards would be broadcasted on its own subnet. Validators would by default trust committees, but if they wish to they could choose to be on every subnet and only accept a beacon block once they see the full body of any shard block that the beacon block confirms.
The sharding spec itself is not exceptionally difficult; it's a boilerplate code change on a similar scale to the recently released Altair hard fork (the Altair [beacon change spec file](https://raw.githubusercontent.com/ethereum/consensus-specs/dev/specs/altair/beacon-chain.md) is 728 lines long, the sharding [beacon change spec file](https://raw.githubusercontent.com/ethereum/consensus-specs/dev/specs/sharding/beacon-chain.md) is 888 lines long), and so it's reasonable to expect it could be implemented on a similar timeframe to Altair's implementation and deployment.
To make sharded data actually usable by rollups, rollups would need to be able to make proofs going into sharded data. There are two options:
1. Add the `BEACONBLOCKROOT` opcode; rollups would add code to verify Merkle proofs rooted in historical beacon chain block roots.
2. Add [future-proof state and history access precompiles](https://ethresear.ch/t/future-proof-shard-and-history-access-precompiles/9781), so that rollups would not need to change their code if the commitment scheme changes in the future.
This would increase rollup data space to **~2 MB per slot** (250 kB per shard * 4 shards, plus the expanded calldata from step 1).
### Step 3: N shards, committee-secured
Increase the number of active shards from 4 to 64. Shard data would now go into subnets, and so by this point the P2P layer must have been hardened enough to make splitting into a much larger number of subnets viable. The security of the data availability would be honest-majority-based, relying on the security of the committees.
This would increase rollup data space to **~16 MB per slot** (250 kB per shard * 64 shards); we assume that at this point rollups will have migrated off of the exec chain.
### Step 4: data availability sampling (DAS)
Add [data availability sampling](https://hackmd.io/@vbuterin/das) to ensure a higher level of security, protecting users even in the event of a dishonest majority attack. Data availability sampling could be rolled out in stages: first, in a non-binding way to allow the network to test it, and then as a requirement to accept a beacon block, and even then perhaps on some clients before others.
Once data availability sampling is fully introduced, the sharding rollout is complete.
## Optimistic and ZK rollups under sharding
One major difference between the sharding world and the status quo is that in the sharding world, it will not be possible for rollup data to actually be part of the transaction that is submitting a rollup block into the smart contract. Instead, the data publication step and the rollup block submission step will have to be separate: first, the data publication step puts the data on chain (into the shards), and then the submission step submits its header, along with a proof pointing to the underlying data.
Optimism and Arbitrum already use a two-step design for rollup-block submission, so this would be a small code change for both.
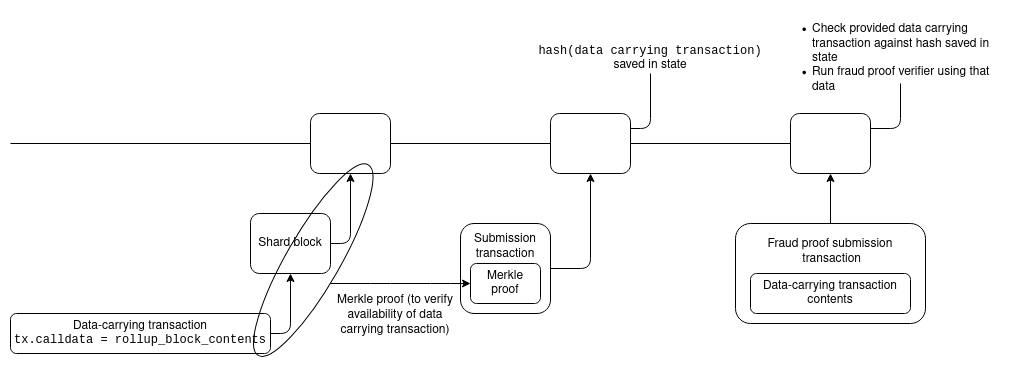
For ZK rollups, things are somewhat more tricky, because a submission transaction needs to provide a proof that operates directly over the data. They could do a ZK-SNARK of the proof that the data in the shards matches the commitment on the beacon chain, but this is very expensive. Fortunately, there are cheaper alternatives.
If the ZK-SNARK is a BLS12-381-based PLONK proof, then they could simply directly include the shard data commitment as an input. The BLS12-381 shard data commitment is a KZG commitment, the same type of commitment in [PLONK](https://vitalik.ca/general/2019/09/22/plonk.html), and so it could simply be passed directly into the proof as a public input.
If the ZK-SNARK uses some different scheme (or even just BLS12-381 PLONK but with a bigger trusted setup), it can include its own commitment to the data, and use a [proof of equivalence](https://ethresear.ch/t/easy-proof-of-equivalence-between-multiple-polynomial-commitment-schemes-to-the-same-data/8188) to verify that that commitment in the proof and the commitment in the beacon chain are committing to the same data.
## Who would store historical data under sharding?
A necessary co-requisite to increasing data space is removing the property that the Ethereum core protocol is responsible for permanently maintaining all of the data that it comes to consensus on. The amount of data is simply too large to require this. For example:
* EIP 4488 leads to a theoretical maximum chain size of ~1,262,861 bytes per 12 sec slot, or ~3.0 TB per year, though in practice ~250-1000 GB per year is more likely especially at the beginning
* 4 shards (1 MB per slot) adds an additional (virtually guaranteed) ~2.5 TB per year
* 64 shards (16 MB per slot) leads to a total (virtually guaranteed) ~40 TB storage per year
Most users' hard drives are between 256 GB and 2 TB in size, and 1 TB seems like the median. An internal poll in a group of blockchain researchers:
<center>

</center>
This means that users can afford to run a node today, but could not if any part of this roadmap is implemented without further modification. Much larger drives are available, but users would have to go out of their way to buy them, significantly increasing the complexity of running a node. The leading solution to this is [EIP 4444](https://eips.ethereum.org/EIPS/eip-4444), which removes node operators' responsibility to store blocks or receipts older than 1 year. In the context of sharding, this period will likely be shortened further, and nodes would only be responsible for the shards on the subnets that they are actively participating in.
This leaves open the question: **if the Ethereum core protocol will not store this data, who will?**
First of all, it's important to remember that even with sharding, the amount of data will not be _that_ large. Yes, 40 TB per year is out of reach of individuals running "default" consumer hardware (in fact, even 1 TB per year is). However, it's well within the reach of a dedicated single individual willing to put some resources and work into storing the data. [Here](https://eshop.macsales.com/item/OWC/MEQCTSRT48/) is a 48 TB HDD for $1729 and [here](https://www.bestbuy.com/site/wd-easystore-14tb-external-usb-3-0-hard-drive-black/6425303.p?skuId=6425303) is 14 TB for ~$420. Someone running a single 32 ETH validator slot could pay to store the entire post-sharding chain out of staking rewards. So the case where literally no one will store some historical data of some shard to the point that it becomes completely lost to humanity seems impossible.
So who will store this data? Some ideas:
* Individual and institutional volunteers
* Block explorers ([etherchain.org](https://etherchain.org), [etherscan.io](https://etherscan.io), [amberdata.io](https://amberdata.io)...) would definitely store all of it, because providing the data to users is their business model.
* Rollup DAOs nominating and paying participants to store and provide the history relevant to their rollup
* History could be uploaded and shared through torrents
* Clients could voluntarily choose to each store a random 0.05% of the chain history (using [erasure coding](https://blog.ethereum.org/2014/08/16/secret-sharing-erasure-coding-guide-aspiring-dropbox-decentralizer/) so you'd need many clients to drop offline at the same time to lose even a single piece).
* Clients in the [Portal Network](https://github.com/ethereum/portal-network-specs) could store random portions of chain history, and the Portal Network would automatically direct requests for data to the nodes that have it.
* Historical data storage could be incentivized in-protocol.
* Protocols like [TheGraph](https://thegraph.com/en/) can create incentivized marketplaces where clients pay servers for historical data with Merkle proofs of its correctness. This creates an incentive for people and institutions to run servers that store historical data and provide it on demand.
Some of these solutions (individual and institutional volunteers, block explorers) are available already. The p2p torrent scene in particular is an excellent example of a largely volunteer-driven ecosystem storing many terabytes of content. The remaining protocol-based solutions are more powerful, because they offer incentives, but they would take longer to be developed. In the long term, it's very possible that history access will be _more_ efficient through these second-layer protocols than it is through the Ethereum protocol today.