owned this note
owned this note
Published
Linked with GitHub
# Verkle transition
## Considerations
- Resource use: CPU, Disk, Cost, I/O
- Syncing and Sync complexity increase
- Complexity of Implimentation and Testing
- Time for conversion to take place
- Ideological
## Methods
### Overview
|Method|Overlay|Conversion node|Local bulk|State expiry|
|------|-------|-------|----------|-|
|Pros| - Low disk use <br />- Easier testing <br /> - Resilient to reorgs<br /> - List of changed leaves in proofs<br /> - Clear sync strategy: all new stuff is verkle sync and all old stuff is snap sync<br />- verification is part of the consensus|- Theoretically faster conversion since we have special nodes to perform them <br /> - Easier for low powered machines to handle <br /> - Lower network wide CPU use => likely fewer missed slots due to resource constraints <br /> - No unexpected i/o bottlenecks on live nodes <br /> - Time to conversion is as long as the slowest recommended download speed of any node on the network <br /> - Could perhaps connect to offline nodes via a new API, allow for more implementations to get the data via torrents/CDNs or Validate data/etc => more resilience | - Ideologically sound, i.e everyone converts data themselves locally <br /> - Testing is more straightforward |- No transition needed<br />- All advantages of the overlay method still hold<br />- No extra work for the nodes during the transition period<br />- Conversion process can take months and not be a problem|
|Cons| - Each client has a different DB structure, meaning that each client would have to figure out how this system would work on their DB => Higher implimentation complexity <br /> - Snap sync might be harder (although snap sync could sync till fork_begin and finish healing before applying conversion to get to head state) <br /> - Gas cost discrepancy between Verkle and MPT leads to attack vector <br /> - Could take longer <br /> - Bulk node hashing optimization is less efficient | - 2x trie => 2x disk requirement <br /> - Bulk node hashing optimization is less efficient <br /> - Catchup is tricky in case of re-orgs <br /> - Gas costs not designed for this level of CPU/IO use => potential DoS vectors | - Over 2x trie => Over 2x disk requirement <br /> - Catchup is tricky in case of re-orgs <br /> - Sync is hard. e.g: If snap sync is in progress before the last day of the fork_end, then during its catchup the required blocks might not be available |- Adds another potentially long research effort as a dependency of verkle, while the state keeps growing<br />- Unlike the overlay method, all the MPT data has to be kept during the conversion<br />- Preimages will be needed for a longer time|
### "Overlay" live conversion method
#### Conversion process
The overlay algorithm involves two sets of trees: the base set and the overlay set. The base set contains an account (Merkle) tree and all the storage (Merkle) trees associated with those accounts, while the overlay set consists of a single verkle tree that is initially empty. The algorithm uses two iterators, one for the account tree and one for the storage tree, to keep track of progress from one block to the next during the conversion process.
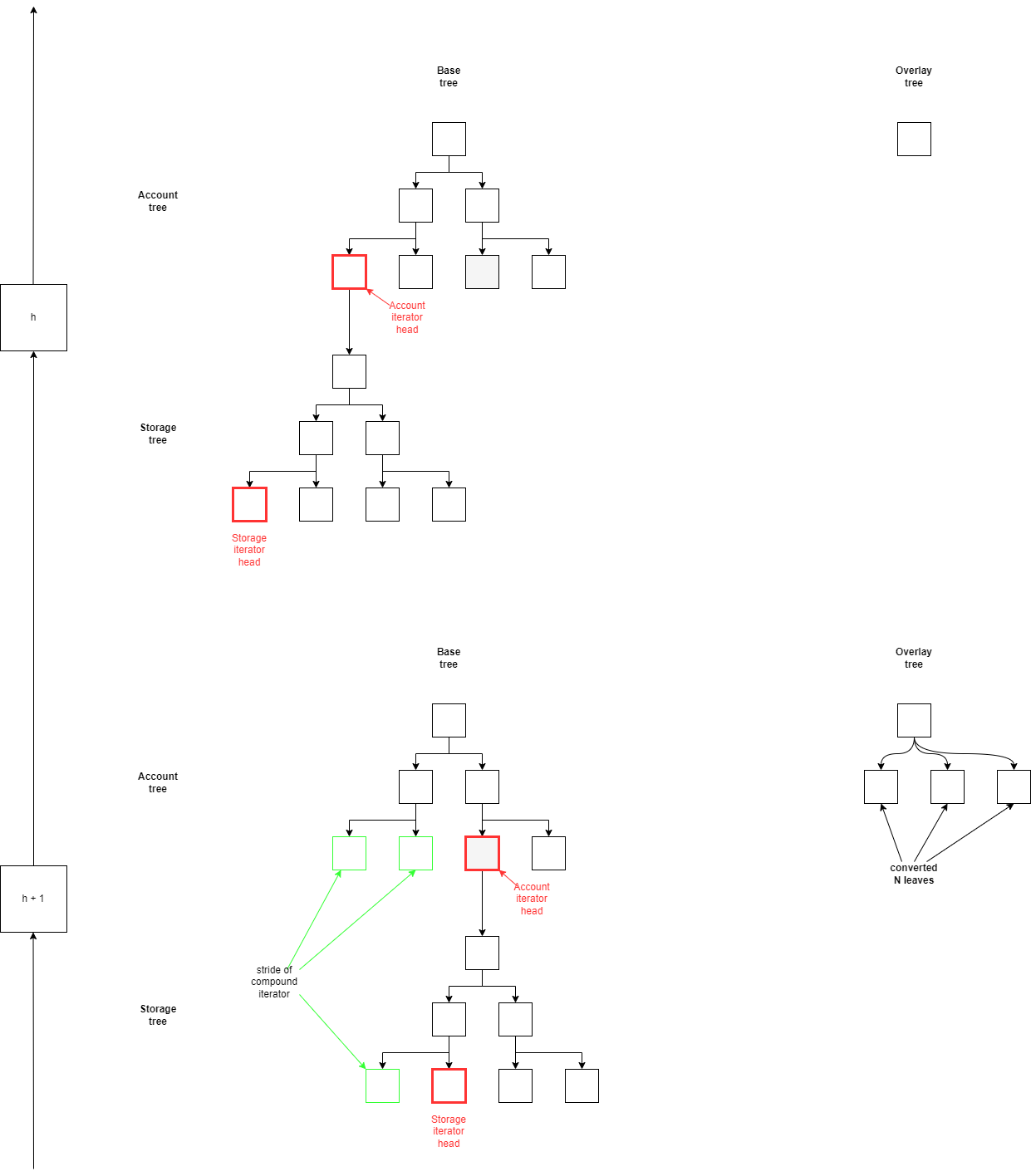
At the start of each block, both iterators progress by a global constant increment of `N` steps. The key range covered by these `N` steps is converted to the verkle scheme and the values are inserted into the overlay tree. These two iterators thus define a "conversion boundary" in which everything before the boundary has been converted and everything after has yet to be.
Then block execution proceeds as normal, with the following tweaks to the tree update algorithm:
* When reading:
- Look for the key in the overlay tree. If a value is found, return it;
- Else, look for the key in the MPT. If a value is found, then return the value.
- Otherwise, return a missing value.
* When writing:
- Any writes end up in the overlay verkle tree, the base MPT is read-only.
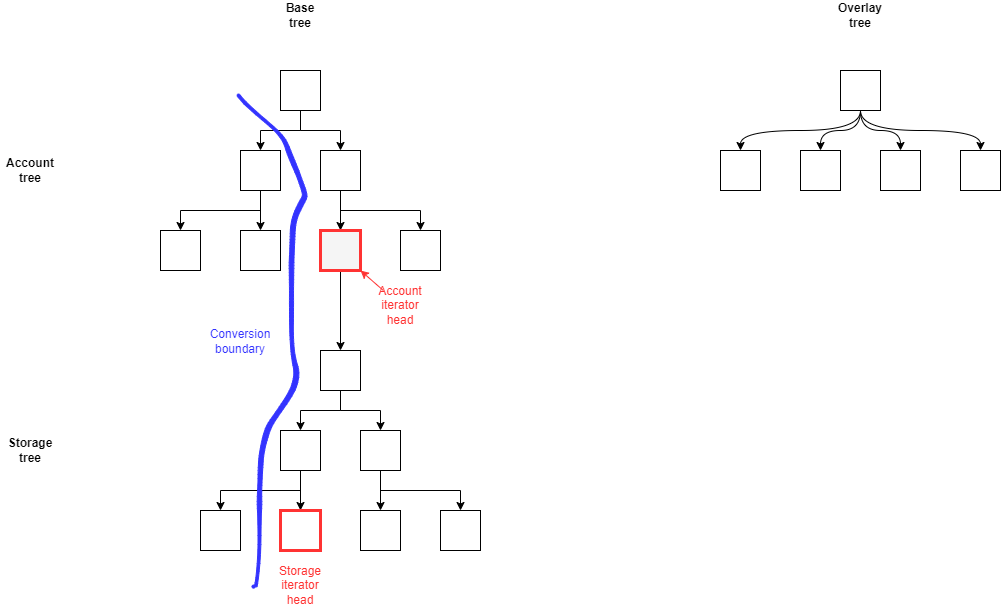
An optimization can be made by considering the execution boundary in hash (keccak) order:
1. Reads from a location left of the conversion boundary: These reads are performed from the verkle tree, since all keys in that space have already been converted.
2. Reads from a location right of the conversion boundary:
- Look for the key in the overlay tree first, in case the value hasn't been converted from the iterator sweep, but was overwritten during the execution of the transition function. If a value is found, return it;
- Else, look for the key in the MPT. If a value is found, then return the value.
- Otherwise, return a missing value.
5. Any writes end up in the overlay verkle tree, the base MPT is read-only.
Since keys that were converted (that is, keys left of the conversion boundary and keys that have been converted during block execution) will no longer be accessed, clients are free to delete their nodes at the finalization block height. This ensure that only a small increase in the disk space is required. The tree root should not be updated in any case, as the base tree remains "virtually read-only".
#### Sync
The advantage of this approach its the simplicity of its sync:
* The base tree is downloaded using snap sync
* The overlay tree is reconstructed from the block witness
Since the base tree is read-only, snap sync will download up-to-date data and the healing phase is unnecessary. There still needs to be some nodes on the network that will keep the entire state for other peers to sync the whole state from.
#### Reorgs
Reorgs of the Merkle tree are relatively easy since the tree is read-only, and that the iterators can be rewound by `N` steps. Nodes before the conversion boundary can not be deleted before their conversion height is deeper than the finalization height.
The verkle tree uses the regular method for reorgs.
#### Acceptance criteria
There are about 220M accounts in the tree, and 600M storage slots. For the transition to happen in an acceptable time, say 1 month, and assuming that 95% of blocks are produced, `N` should be:
$$
N \ge \frac{10^{9}}{\frac{3600}{12} * 24 * 30 * 0.95} \approx 4873
$$
This is ~3 times the number of leaves that are touched per block[^caveat_replay], so it would only represent an increase in disk accesses, but not by an order of magnitude. This can be further mitigated by artificially increasing the gas cost during the transition period[^caveat_rig].
[^caveat_replay]: This is an estimate based on gas costs. TBC when replaying a recent payload, which is work in progress
[^caveat_rig]: RIG's input on this would be needed
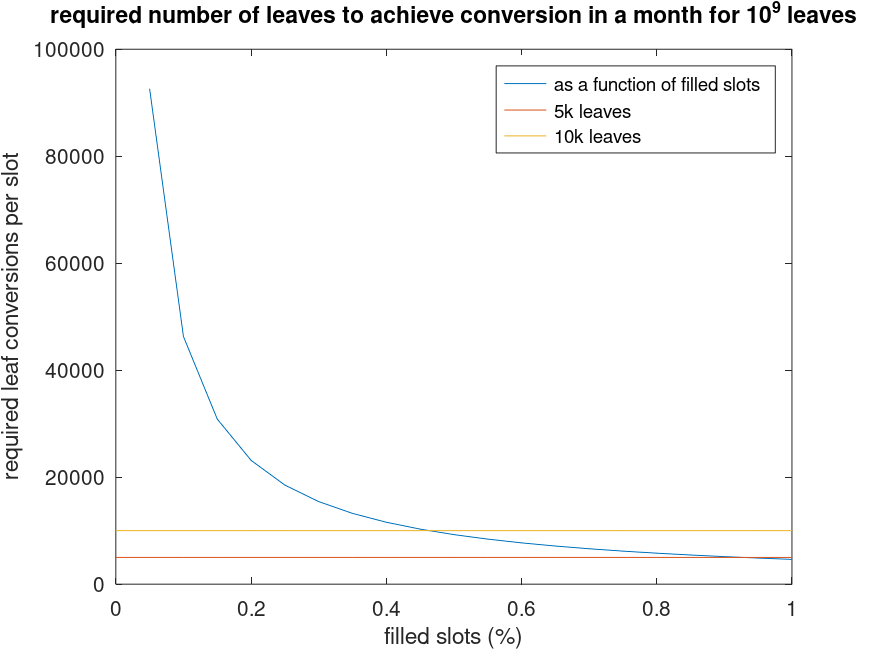
This graph shows that it should be possible to miss 20% of the slots and still convert a reasonably low amount of leaves per slot, to achieve the goal in under a month.
### Conversion node method
#### Conversion process
The conversion node method introduces one new class of nodes, these will be referred to as "conversion" nodes. These nodes shall go offline at the `fork_begin` height and shall convert the entire state from MPT to Verkle until that height. The conversion nodes will additionally ensure that they wait until the `fork_begin` height has been finalized to ensure no re-org can occur. The regular nodes on the network shall continue operating as normal, but they will record all the new payloads and forkchoice update messages from the moment of `fork_begin` for replay on top of the converted state.
The conversion nodes shall be expected to optimize for high CPU, disk and I/O requirements. They may serve the converted state once the conversion has been done and validated. This conversion needs to be done well before `fork_end` so as to ensure every node has ample time to fetch the converted state and valdiate it if necessary. Since the state is frozen at the point of `fork_begin` we can make use of sharing methods such as Torrents, CDNs as well as other tools in order to efficiently share the state with low overhead. Each user can decide to fetch the state from a trusted party (and validate) or if they prefer to perform an offline conversion themselves.
Once regular nodes have pulled the state from a conversion node, the regular node must apply all of its new payload and fcu messages to the Verkle state so as to bring it to head.
At the point of `fork_end`, all nodes on the network shall switch over from MPT to Verkle.
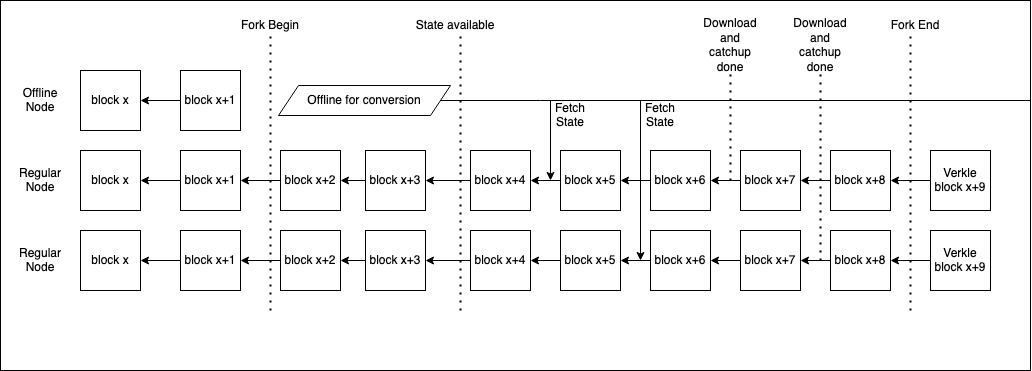
#### Sync
If a node is offline during `fork_begin` it would lead to it not knowing the payloads and fcu's to apply once it has the converted state. We would need the CL to be able to store all payloads and messages to get the converted state to head (Could be tricky with pruning).
This method would introduce a few more states to the sync process, i.e: if a node is in optimistic sync mode, it would have to wait until the node is out of this mode before movind ahead with the conversion process. If the `fork_end` occurs before this, then the network would have to ensure it can still fetch blocks from the network in the MPT state so as to allow such nodes to be able to sync to head.
#### Reorgs
The process of applying the messages needed to bring the node to head needs to be lead by the CL. The assumption is that the CL is aware of the reorgs and will lead the EL successfully till head.
#### Acceptance criteria
Benchmarks with newer code need to be performed to see the amount of time needed by equipped machines as well as an analysis of acceptable download times.
Additionally we need benchmarks as to the overhead of applying the "catch up" messages on every node. This overhead could lead to a CPU/IO bottleneck leading to degraded performance on a regular node. However, this degraded performance would be staggered across the network, depending on when the conversion is started.
We also need to see if the tradeoffs mentioned here are acceptable to the wider community. There are a decent number of changes and new states introduced which might lead to heightened support needed for regular users, especially regarding how/where to fetch the converted state from & what to do if deadlines are missed.
### Local bulk conversion method
#### Conversion process
Every node on the network would start to convert the state it has at `fork_begin`. Since the node is live, any change that touches an uncoverted leaf would have to be copied first. Once the conversion is complete, the node would apply new payload and fork choice updated messages to catch the node up to head. At `fork_end` the node shall switch over from MPT to Verkle.
Since the conversion happens on a live node, we would need to be mindful of the resource overhead this has on the nodees. If done incorrectly, this has the potential to lead to missed slots on Mainnet and that leaves the network at a weaker position.
Since the nodes are under much higher resource node, this could also require a new gas pricing on the EVM to prevent DoS attacks. Since Verkle would require a new gas model as well, we could perform this fork with 2 new gas models. i.e, existing gas prices till `fork_begin`. Modified gas prices that takes into account the heightened load between `fork_begin` and `fork_end`. Finally a new gas model that takes into consideration Verkle after `fork_end`.
The disk space requirement will be higher than 2x since the changes the node makes to the MPT state will also have to be copied over so as to convert a "frozen" state to Verkle.
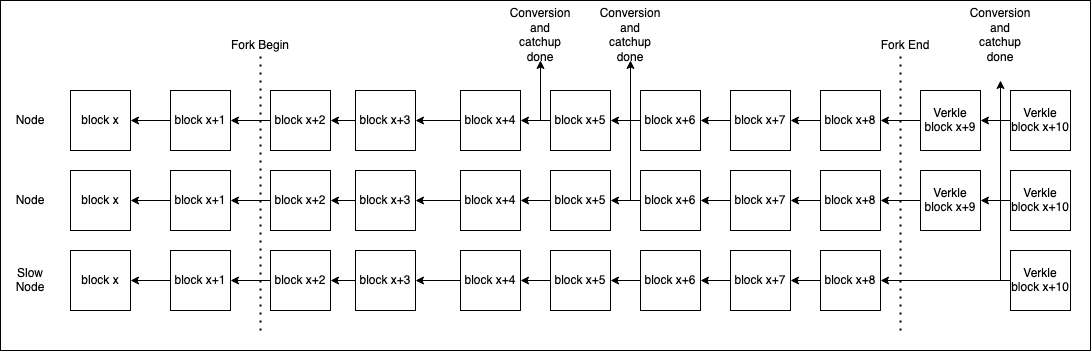
#### Sync
If a node is offline during `fork_begin` it would lead to it not knowing the payloads and fcu's to apply once it has the converted state. We would need the CL to be able to store all payloads and messages to get the converted state to head (Could be tricky with pruning).
The node serving sync state would need to be mindful of serving the non-converted state to the peers. The peer would then be considered synced when it has a MPT state and would then have to start a fresh conversion of its state to Verkle. This could lead to the node not being done with the conversion before `fork_end` and subsequent downtime.
#### Reorgs
Reorgs would be quite tricky as the reorg would have to take account of the "copied" over MPT state as the conversion is applied on the "frozen" state at `fork_begin`. One would need to undo the change and re-apply the reorg state and copy over a new changeset.
#### Acceptance criteria
A deep analysis needs to be made on the various database structures and if such a live transition is even possible on all the clients.
A benchmark needs to be run to find the overhead associated with the conversion while the node is live. It could be that the conversion process needs to take significantly longer so as to allow for lower powered machines to keep up with the network tasks as well as the conversion duties.
### State expiry
#### Conversion process
Freeze the MPT, start with a fresh tree, defining a new 'era'. Tree access is as follows:
- Reads will first search the verkle tree, returning a value if present in the tree
- If the previous read fails, the MPT is searched, and the value of that search is returned
- All writes go to the verkle tree
A (potentially offline) conversion process occurs in the background, and the result can be downloaded.
#### Sync
Same as the overlay tree: download the MPT in snap sync with no healing, and the verkle tree with verkle sync.
#### Reorg
The MPT is read-only, except when reorging across the era boundary, in which case the the tree will be modified until the head crosses the era boundary, and the MPT is frozen again.
#### Acceptance criteria
TODO
## Benchmarks
### Estimates for computing `N` (ongoing)
Method: perform a state conversion while replaying blocks or following mainnet
Key indicator:
- Time taken
- RAM usage
- extra disk space
|Machine|N|Time per block|Total time|RAM|Extra disk space|
|-------|-|--------------|----------|---|----------------|
|asrock AMD Ryzen 7 5800U|1K|100ms (average) 300ms (worst case)|5 months (estimate)|N/A|N/A|
|asrock AMD Ryzen 7 5800U|10K|300ms (average) 1s (worst case)|15 days|8GB|NA|
|rocks 5B|1K|403ms (average) 995ms (worst case)|5 months|16GB|NA|
|rocks 5B|10K|2s (average) 4s (worst case)|15 days|16GB|NA|
### Estimates for an offline conversion (ongoing)
Method: run the conversion process at a given block height
Key indicator:
- Time
- RAM consumption
|Machine|RAM|Time|
|-|-|-|
|x5.large|||
|rock 5B|||
|beefy security machine|||
|asrock|||
|Macbook M1|||
### Estimates for download time (TODO)
### Estimates for block replay (ongoing)
Method: replay a chain segment in verkle mode, based on a converted database.
Key indicators:
- RAM usage
- temporary disk usage
- CPU usage





